

Announcing KiQT – The Kinesis Quality Toolkit
Announcing KiQT – The Kinesis Quality Toolkit

Linda Navarette
Linda Navarette June 27, 2019
Imagine building a weather signal ingestion pipeline to compute average temperature across all sensors in a given postal code for a global weather application. You have 150,000 sensors across the US reporting weather signals every ten seconds, and need to group those by postal code to compute the average, minimum, and maximum temperature reading. Our team recently worked with a client to create a similar IOT data processing and data analytics pipeline. For our implementation we chose to use Amazon Kinesis for a few reasons:
-
It’s completely real-time; data can be processed and ingested as it is received from sensors. This provides a huge advantage over a more traditional batch-processing pipeline.
-
It’s fully managed and pay-as-you-go; this provides cost savings over hosting and managing our own pipeline using a similar streaming platform like Apache Kafka.
-
It’s scalable; as coverage for the weather application increases and more sensors are added we can easily scale up the pipeline accordingly.

The architecture of such a streaming pipeline leveraging Amazon Kinesis would look something like this:
To accomplish the computations, Kinesis Data Analytics gives developers two options: SQL and Java (Apache Flink). For this exercise, we chose the SQL runtime because it is simpler to write, costs less to run, and the AWS console provides the ability to inspect intermediate computations while the application is running. We also wanted to set up automated testing to validate the proper functionality of our application as changes were made. The scenarios we were looking to test included:
-
Given a set of weather signals, the average, minimum, and maximum temperature should be accurately computed for each postal code
-
Given one slightly late arriving weather signal (in the event one of the sensors is offline and can’t immediately communicate its signal), the average, minimum, and maximum temperature readings should be updated accordingly
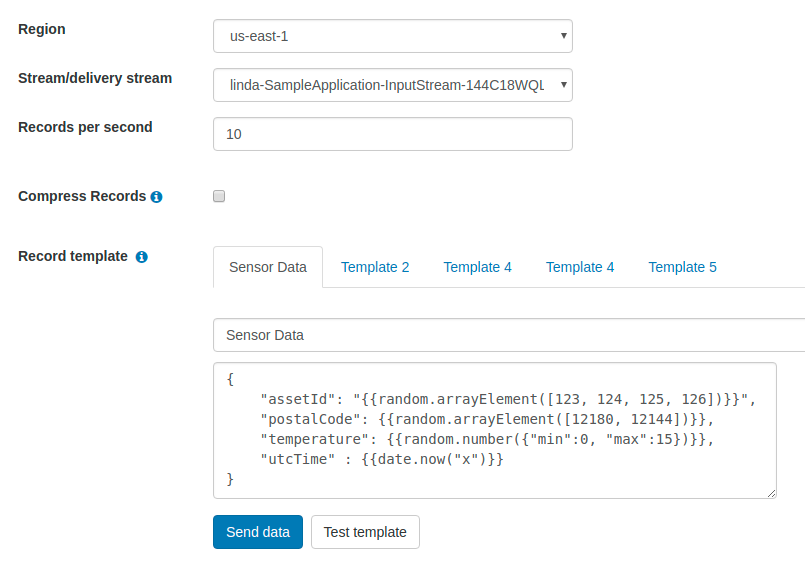
Testing these types of architectures can be complex given the real-time nature of the data and the fact that, because the SQL code cannot be unit tested, all of the validation must be done in functional testing. We took a look at the Kinesis Data Analytics best practices for some guidance around testing. The documentation recommends using the Kinesis Data Generator, a configurable data generator that allows a user to specify a data template and input stream. While this is a useful tool for generating data to smoke test or load test a streaming application, for functional tests, it still falls short in a few important ways:
-
The records per second configuration sends a fixed number of records at a fixed interval; this does not enable us to easily simulate the late-arriving data scenario
-
The data generated is not predictable or repeatable; the random variation in signal values doesn’t give us any sense of whether the computed values are accurate
-
The use case is purely data simulation, whereas a functional test also requires reading the output streams and asserting on expected outputs
-
The data generator is a UI, not an extensible library
For these reasons, the Kinesis Data Generator was not a good fit for our functional testing. We began writing a custom test harness that leveraged the Kinesis SDK which would need to:
-
Ensure the application is running
-
Write data for each of the test scenarios to the input stream
-
Poll for records on the output stream matching the expected outputs
-
Poll for records on the error stream – a process similar to polling for records on the output stream but the DATA_ROW (row of data that caused the error) is serialized and hex-encoded
This method required our deployment process to communicate AWS configuration, stream names, and the application name to our tests. To simplify further, we decided to determine the input stream, output stream(s), and error stream by inspecting the details of the running application. We quickly realized that setting up the lifecycle management and streaming I/O we used for our functional tests could be generalized to suit the needs of other streaming applications, so we created the Kinesis Quality Toolkit (KiQT, pronounced ‘kicked’). KiQT allows users to create behavior-driven development style tests around analytics applications given only the default AWS environment configuration and the name of the application under test:
// creates the test harness
ApplicationIOProvider app = new ApplicationIOProvider(“MyApp”);
KinesisQualityTool kiqt = new KinesisQualityTool(app);
// gets the input kinesis stream
kiqt.theInputStream()
// specifies a response handler
.withResponseHandler(response -> {
Long failedRecords = response.failedRecordCount();
Assert.assertEquals(0, failedRecords.longValue());
})
// writes the inputRecords to the input stream
.given(inputRecords);
// gets the output stream named OUTPUT_STREAM_NAME
// and deserializes its records to type OutputRecord
kiqt.theOutput("OUTPUT_STREAM_NAME", OutputRecord.class)
// sets a 30 second timeout for all assertions on this output
.within(30, TimeUnit.SECONDS)
// executes the assertion
.should(Matchers.equalTo(expectedOutput));With KiQT, you can write tests that look and feel like functional tests written against a Java application. Each test case can be defined with only:
-
The name of the application
-
The list of objects to be written to the streaming application
-
The assertions to be made against the application outputs
This enables developers to quickly create and iterate on high-quality test cases and leave the streaming IO up to the toolkit.
Check it out and let us know what you think: https://github.com/Nuvalence/kinesis-quality-toolkit