


Nick OConnor February 6, 2020
At this point you’ve probably already heard of or have had first-hand experience with the security and maintainability benefits provided by containers. Besides being “what the cool kids use”, the ability to ship a complete snapshot of an application with dependencies is incredibly powerful both from maintainability and security perspectives. While many devs are aware of these benefits, the low-level workings of containers are often understandably mysterious since typical devs day-to-day interactions are limited to Docker tooling (i.e. build, tag, run, & push). While this isn’t inherently problematic, having a deeper understanding of the workings of containers is beneficial for creating efficient images, packaging 3rd party software, and debugging live systems.
DIY Containers
https://github.com/Nuvalence/diy-containerAs part of my self-taught course on the inner workings of containers, I set about containerizing httpd (apache) using only commands found on base installs of linux. For those wanting to follow along, my progress is available on github, with inspiration drawn from a post by Aleksandr Guljakev. It requires only a bash shell and stands up a fully-accessible and containerized httpd instance with an alpine linux base. You can also poke around within the container by launching a shell instead of httpd. The repo’s README contains example commands.
Ecosystem
Throughout this post I’ll be referring to “containers” and not “Docker containers”. That’s because multiple runtimes exist! This is great news since it offers hosting flexibility without mandating changes to the development process and pipeline. For instance, runC, containerd, and CRI-O all implement the specification defined by the Linux Foundation’s Open Container Initiative (OCI) and are officially supported by Kubernetes. The OCI spec is comprised of two parts, one defining the image and the other the runtime. While Docker was the first to provide a mainstream runtime, it’s far from the only project to do so. Ian Lewis has a good series differentiating between the more popular runtimes.
Images
Container images consist of root filesystems, providing all of the dependencies required by the containerized application. Images are composed of layers which are mounted by the runtime using a union mount filesystem (usually aufs or overlayfs) in which writes are only performed to the upper-most layer. Since each of the lower layers are immutable, disparate applications may share common layers (i.e. a base distro filesystem or a set of installed dependencies), potentially saving a significant amount of network bandwidth and disk space. Docker provides a in-depth description of layers, as well as how to configure the use of other union mount filesystems.When building images using Dockerfiles, each command corresponds to a layer. Due to this mechanic, it’s important to define logically-reusable steps within Dockerfiles so that they may be used between containers. In the example runtime, the layers reside within the layers directory and are mounted in increasing order using overlayfs by the runtime. I chose to implement a layered container image to show how union filesystems are created and mounted.
Runtimes
The core of the work done by container runtimes is configuration of Linux namespaces and use of chroot. Respectively, these provide virtualization of specific kernel functionality and root filesystems. The namespaces include: pid, network, ipc, uts (hostname), cgroup (resources), mount, and user (uid/gid). I’ll run through a couple of the most obviously impactful. Unshare does the bulk of the namespace management in the example runtime.PID namespaces restrict process visibility within the container and provide a separate process ID pool. Only other processes launched within the container’s assigned namespace are visible. This can be demoed by running ‘ps’ within the runtime: Network namespaces restrict interface and route table visibility within the container, with each namespace having its own network stack. Only interfaces and routes created within the container’s assigned namespace are visible. This can be demoed by running ‘ifconfig’ and ‘route’ within the runtime:
Network namespaces restrict interface and route table visibility within the container, with each namespace having its own network stack. Only interfaces and routes created within the container’s assigned namespace are visible. This can be demoed by running ‘ifconfig’ and ‘route’ within the runtime: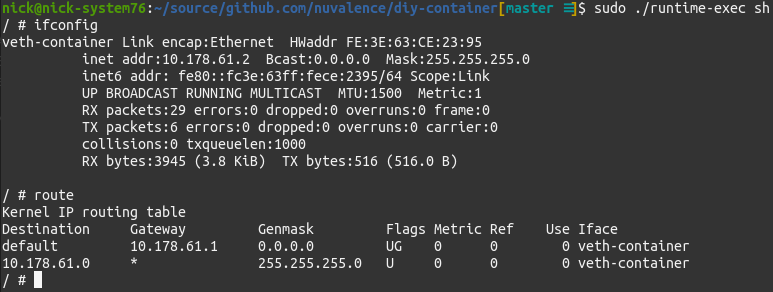 Cgroup namespacing limits and monitors system resources used by the container (e.g. CPU and memory). The currently configured cgroups are exposed in the ‘/sys/fs/cgroup’ directory. Unfortunately demoing them isn’t straightforward since most tools read from ‘/proc/meminfo’ which isn’t namespaced. The example runtime doesn’t limit CPU or memory for this reason. Documentation of how Docker exposes these metrics and limits is available on their website.
Cgroup namespacing limits and monitors system resources used by the container (e.g. CPU and memory). The currently configured cgroups are exposed in the ‘/sys/fs/cgroup’ directory. Unfortunately demoing them isn’t straightforward since most tools read from ‘/proc/meminfo’ which isn’t namespaced. The example runtime doesn’t limit CPU or memory for this reason. Documentation of how Docker exposes these metrics and limits is available on their website.
Feedback
I’d love to hear your feedback as well as any comments or questions regarding containers or what to cover next (I’m thinking Docker CLI tips tricks). Feel free to fork the diy-container repo and play around with containment and tune in next time! Happy hacking!