

The Creative Power of Generative AI for the Enterprise
The Creative Power of Generative AI for the Enterprise

Nuvalence
Nuvalence March 27, 2023
Written by: Dan Hernandez & Jay Reimers
As we enter an era of ubiquitous cognitive automation, leaders need to start thinking about how to pivot their business models and products using AI technologies like Generative AI.
Forward-thinking organizations know they need to seize this moment of unprecedented interest, excitement, and opportunity; they can’t afford a “wait and see” approach.
Fortunately, the advent of Generative AI tooling makes it easier than ever to apply AI to your enterprise use cases. So the question is: in a world where the possibilities are bounded only by your creativity (and token limits!), where do you begin?
At Nuvalence, we’ve been thinking a lot about how we can help our clients tap into the power of AI in a practical way. We recently challenged ourselves to get creative with OpenAI’s GPT models (the power behind ChatGPT). Here’s what we learned.
The Challenge
To date, many of the ChatGPT use cases reason over large bodies of public text data. In the enterprise, much of the useful data is stored as text in private relational databases.
Let’s say you’re a developer on a new e-commerce product. Product managers and executive leadership need data to help guide strategic decision-making, so they frequently come to you for help retrieving numbers from a database. You know it’s important for the success of the new product, but so is work that’s been committed to the product roadmap.
To add to that, growing complexity and frequent changes in the database make these requests time-consuming, taking away from the valuable time you and other experienced team members have to focus on essential features and improvements.
How can you simplify the data retrieval process, require less expertise, and possibly allow stakeholders to access the data themselves? Building an analytics stack might be a long-term solution, but it doesn’t solve the immediate issue (and doesn’t always answer the right questions). What you need is a way to securely and reliably pull useful information from an enterprise system, using natural language.
Enter DataGPT
To address this challenge, let’s envision a fictional product called “DataGPT.” DataGPT serves as a data catalog, enabling users to navigate private datasets through natural language interactions (see example 4 in 4 Ways to Create Business Leverage by Integrating with Conversational AI). The target audience ranges from business analysts to executives, making it a versatile tool for any organization dealing with structured data analysis.
Let’s return to our e-commerce company to watch DataGPT in action. An executive needs to quickly identify trending product categories for an impromptu meeting with a supplier.
In the current landscape, the executive would typically either request the latest data from colleagues, sift through a backlog of emails or chat history to find the most recent figures, or, if a prior investment was made, navigate to a complicated set of analytics dashboards. These methods often result in outdated information, additional workload for already busy teams, or assume significant prior investments.
DataGPT changes all that. It can alleviate pressure on development teams, deliver real-time information, and reduce the urgency for a substantial analytics investment – while being incredibly user-friendly.
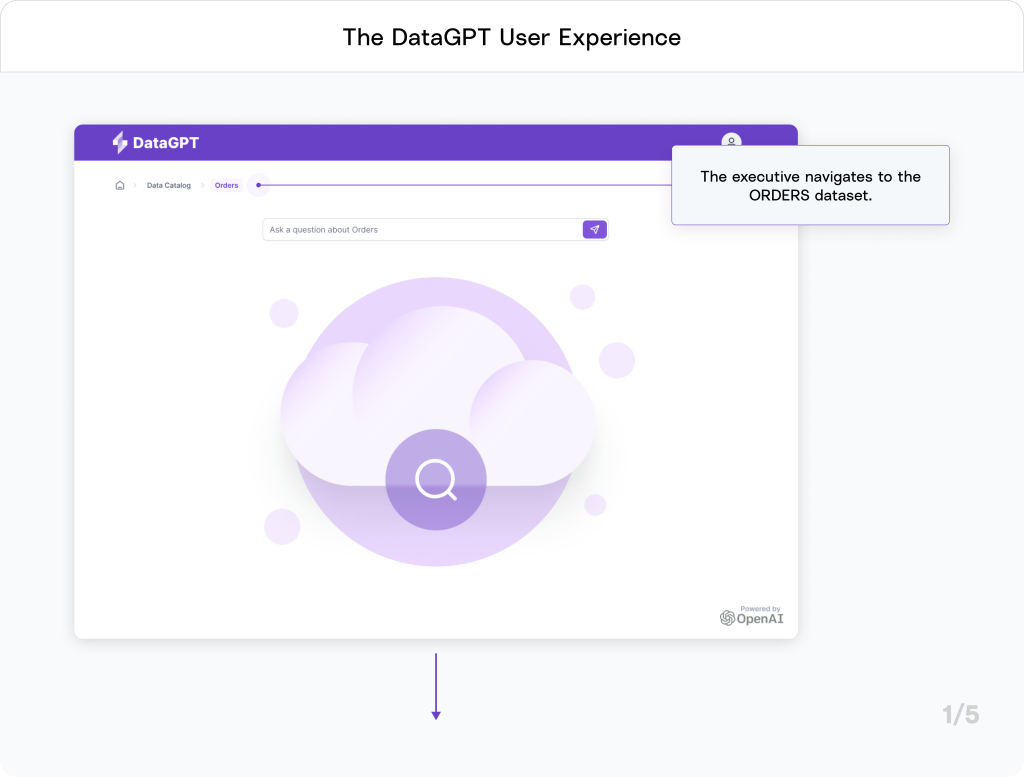
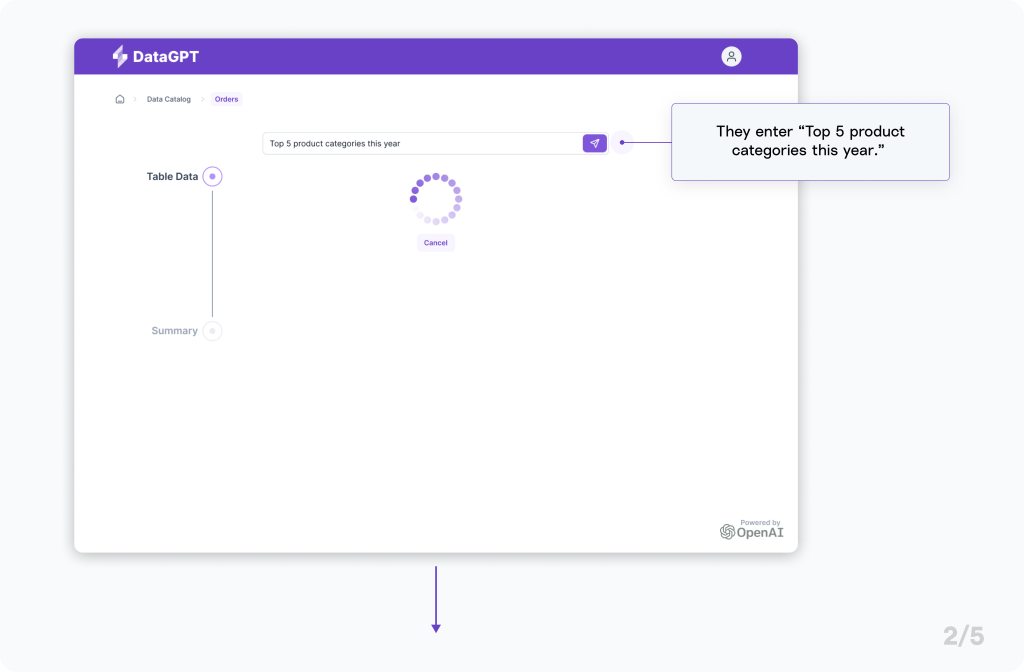
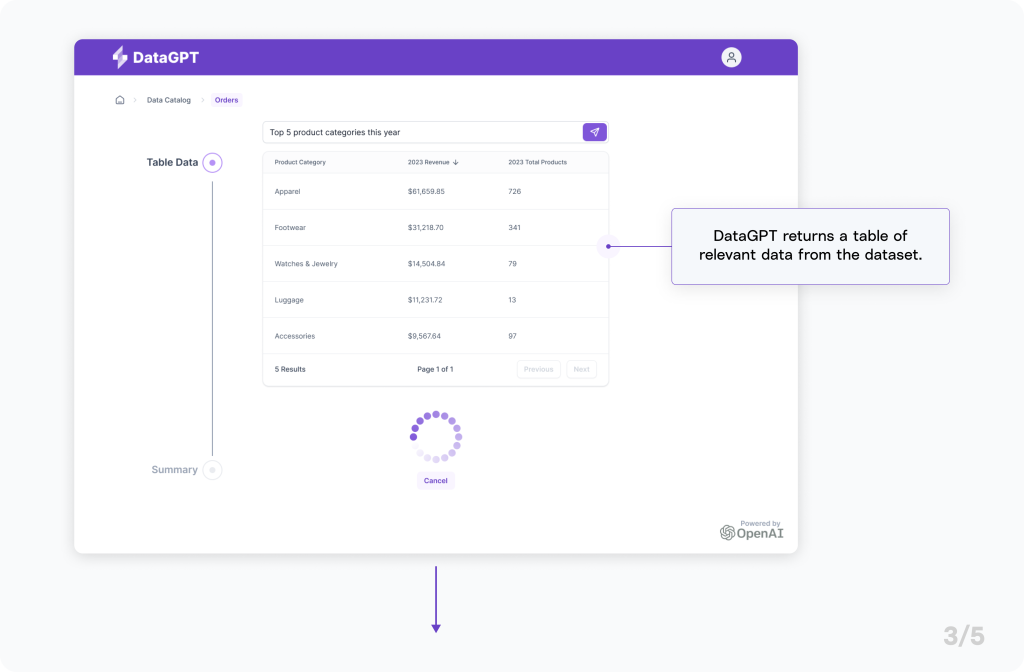
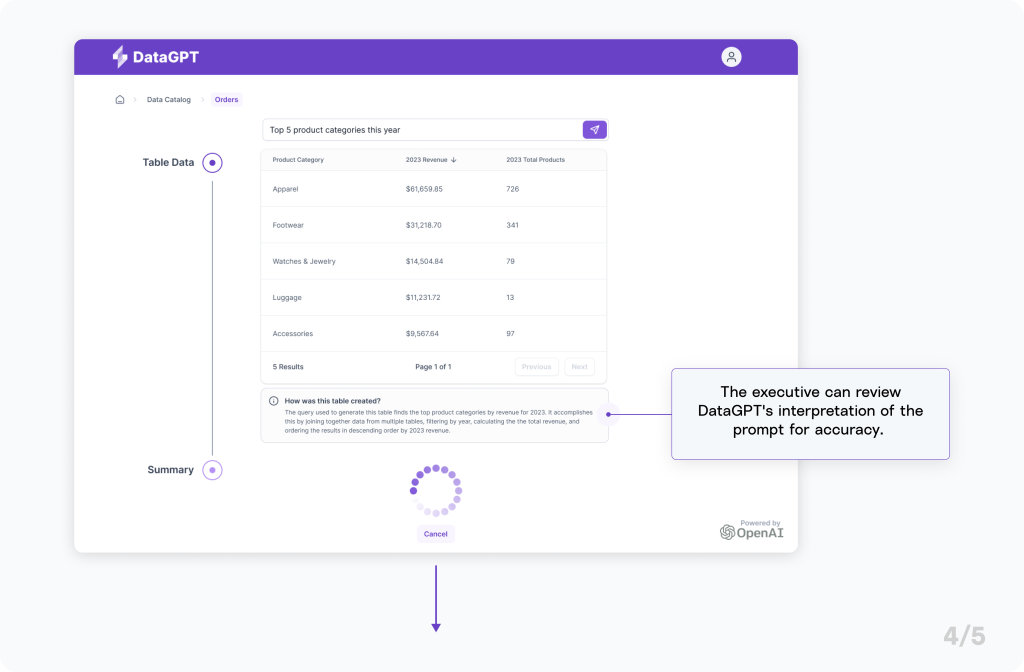
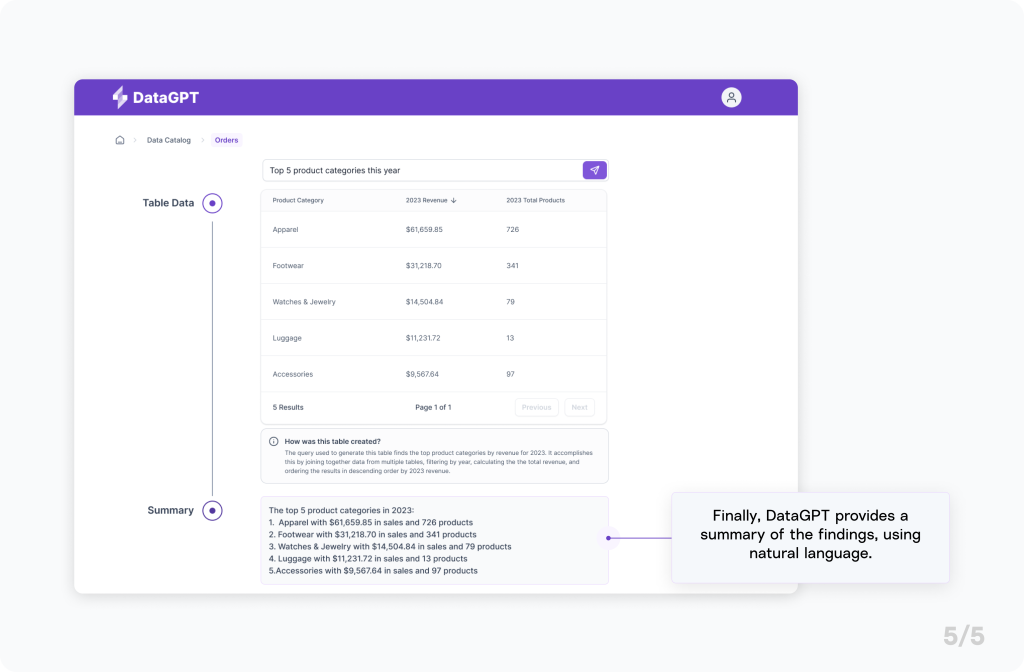
Powering DataGPT with Generative AI
You can see how this experience is designed to be approachable for anyone. What’s more, the availability of powerful, user-friendly tools enabled us to develop our proof of concept in just a few days.
Now that you’ve seen the front-end, let’s dive into the backend and how it all fits together.
You might ask: Is OpenAI’s Large Language Model (LLM) trained with this private and potentially sensitive data? Wouldn’t that require significant machine learning expertise and create privacy concerns?
The short answer is no: the application uses Generative AI to elicit SQL queries in response to natural language. Now, of course, public LLMs aren’t capable of knowing how a private dataset is structured, so DataGPT cleverly provides that information along with the input from the user. In response, DataGPT receives a SQL query that it can use to safely extract data from the dataset and provide the results back to the user (and then some).
See the high-level actions that support the DataGPT experience below.
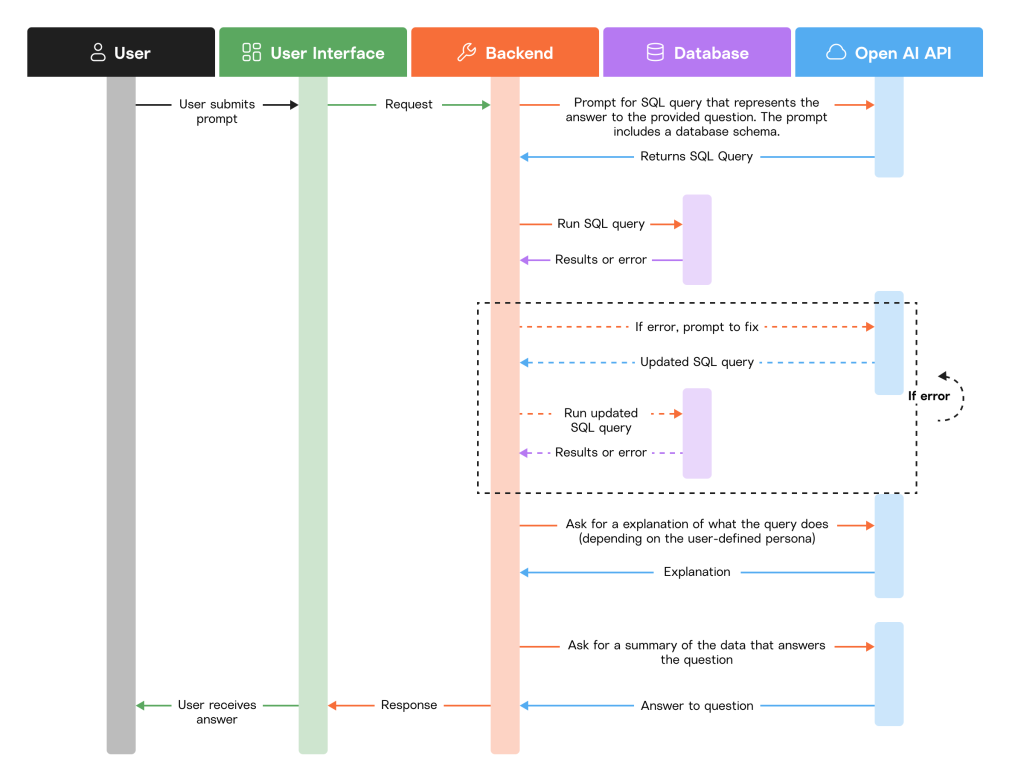
Building DataGPT as an Enterprise Application
Building a product like DataGPT in an enterprise setting requires a number of steps and components. To help convey the nuances of building a Generative AI enterprise application, we worked through a proof of concept (available in GitHub).
When we started this challenge, we expected to complete the following steps:
- Build a prompt from:
– The user’s question
– Schemas of the available tables along with sample data
– Clear directions on the desired SQL result
… and then run it through the latest GPT model and get up to three completions of raw SQL. - Execute the SQL against the relevant tables.
- Run the result back through GPT for a natural language summarization and return the result and summary to the user.
In the end, we found that some assumptions did not hold up, and also discovered some additional steps we didn’t anticipate.
Before you start – Connecting to OpenAI APIs, deciding on a model, and creating a dataset
First and foremost, you’ll need an OpenAI API key. You can get one by signing up for an account. Similar to many other cloud-based API products, it’s free to get started.
We needed to decide which OpenAI model that we wanted to use. After testing a few, we ultimately landed on the latest GPT-3.5 turbo model. We determined that this model was the most effective at comprehending intent when generating SQL queries, despite there being models specifically tailored to code completion, such as Codex (which is no longer supported by OpenAI, as of this writing).
In terms of sample data, we explored a number of options before deciding on an open source e-commerce database with orders, products, payments, etc. We initially were worried that we would hit token limitations with the number of tables, but found that we were able to support the full schema by removing the need to provide sample data in the prompt.
Step 1 – Building the initial prompt
Building prompts for GPT models can sometimes feel like more of an art than a science. Knowing what context to provide, how to phrase the request, and which personas to assume are all important in achieving the desired outcome. Prompt engineers, whose expertise is specialized in knowing how to ask AI the right questions to get the most accurate result, are in increasing demand. And new products are popping up to help as well.
For DataGPT, we found that the initial prompt required three elements:
- A summary of the dataset’s structure
- The user’s question
- The technology of choice for the returning query (we used Postgres)
We followed various paths to understand what the prompt needed. At first, we included sample data from each table. Upon realizing this didn’t increase the accuracy of the generated SQL, we removed this element to preserve the number of request tokens.
We had also initially found that the generated SQL often selected the primary key of the table (i.e. a sequential number), which was meaningless to a user. By instructing GPT to prefer names over ids, we were able to overcome this.
Here’s the resulting template for the prompt:
val prompt = """
$tableSummaries
Given the above schemas, write a detailed and correct Postgres sql query to answer the analytical question:
"$question"
The query should prefer names over ids. Return only the query.
"""When provided with data, it takes the following form, which would be passed to the OpenAI chat completion API:
Schema for table: order
id integer
customer integer
ordertimestamp timestamp with time zone
shippingaddressid integer
total money
shippingcost money
Schema for table: order_positions
id integer
orderid integer
articleid integer
amount smallint
price money
Schema for table: products
id integer
name text
labelid integer
category category
gender gender
currentlyactive boolean
Given the above schemas, write a detailed and correct Postgres sql query to answer the analytical question:
"Which product category was trending in 2018?"
The query should prefer names over ids. Return only the query.Step 2 – Checking the query
Testing revealed that the generated query didn’t always match our expectations, which raises the question of accuracy. There are two aspects to consider: whether the query is syntactically correct, and whether it answers the question accurately.
In most cases, GPT can create a syntactically correct query, but the answer’s accuracy can vary, particularly with complex questions. To tackle this issue, we requested multiple options and selected the most suitable.
Another constraint to consider is the current model’s prompt limit. As of the writing of this post, the limit for our model was 4,000 tokens, restricting the database’s size and complexity. However, OpenAI’s token limits have historically increased with new models, and we can expect this constraint to lift soon. In fact, with the release of GPT-4, the token limit will increase up to 32,000. One way to work around this constraint today is by chaining together queries and responses, refining as you go. You could even ask GPT if the query is ready based on a set of rules.
Still, while the initial queries were mostly correct, the GPT model would make common mistakes, such as using LIKE instead of ILIKE (which resulted in no results on case mismatch). So we augmented the initial query prompt asking GPT to fix this and other common mistakes:
val prompt = """
...
Avoid common Postgres query mistakes, including:
- Handling case sensitivity, e.g. using ILIKE instead of LIKE
- Ensuring the join columns are correct
- Casting values to the appropriate type
- Properly quoting identifiers
- Coalescing null values
"""Step 3 – Running the generated query and fixing any errors
Next, we ran each generated query against the database and attempted to find the “best” query, which we determined by affirming whether the next query returned the same number of rows. If so, we stopped. Otherwise, we continued to evaluate the remaining queries. If a query returned no rows, we asked GPT to rewrite the query. Meanwhile, if the query resulted in an error, we took advantage of the additional context the error provided to help GPT fix it, as shown below. GPT was generally able to take the hint and produce a new, valid query.
val prompt = """
$sql
The Postgres sql query above produced the following error:
PSQLException: ERROR: column p1.store_id does not exist
Hint: Perhaps you meant to reference the column "s1.store_id".
Position: 157
Rewrite the Postgres sql query with the error fixed.
"""Reinforcement learning from human feedback (RLHF), as demonstrated in our error message example or in human-in-the-loop approaches, is a core principle of GPT models and should be a part of any production model. One could imagine that this programmatic approach could allow the models to self-learn and become even more accurate with continued usage.
Step 4 – Summarizing the results
After identifying the best query, we needed to make sure that the results would be returned to the user in a way that made sense to them. We did this by offering a persona-specific, natural-language summary that included an interpretation of the prompt for context.
While the natural language summary isn’t actually part of the query, this chatbot-like experience is the key to keeping DataGPT approachable and user-friendly for a variety of non-technical audiences.
For instance, consider the earlier prompt: “Top 5 product categories this year.”
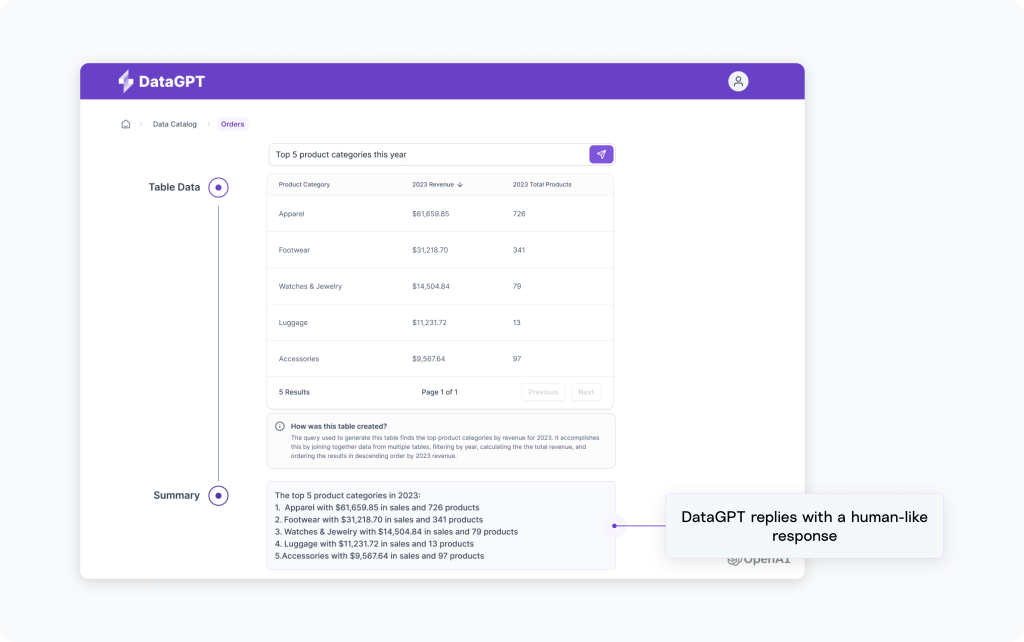
We also asked GPT to explain the generated SQL query to help the user verify that the right query was used based on the intent of their question.
And we even decided to take it a step further and asked GPT to assume a persona, tailoring the query explanation to the user. Whether you are a senior data analyst or an executive, you’d receive an understandable explanation with just the right amount of detail. In a real-world scenario, the persona could be implied based on role-based access control (RBAC).
But is it secure?
We are asking GPT to generate a raw SQL query, and in doing so are entrusting GPT to truthfully answer the question. How do we prevent the unauthorized release of data? There are a few choices.
Creating data boundaries such as leveraging a relational database management system (RDBMS)’s multi-tenancy feature is one possible solution. OpenAI’s Chat Markup Language (ChatML), a new query language for prompts, is another. Like using parameterized queries in SQL to mitigate against SQL injection, ChatML distinguishes system versus user content to mitigate against prompt injection, where a user craftily constructs a prompt to make the application do something it wasn’t intended to do.
In terms of privacy, OpenAI has made recent changes to their data retention policies. They no longer use data submitted through the API for service improvements or model training, and they have implemented a default 30-day data retention policy, with the option for stricter retention if necessary.
However, it’s important to note that the OpenAI GPT API runs on shared compute infrastructure by default. Organizations that are more security-conscious can opt to provision dedicated instances in Microsoft Azure.
Conclusion
Stepping back, it becomes evident that this pattern, along with others employing Generative AI, can be applied to a wide range of use cases. From building end-user data exploration features to empowering internal teams and managers to delve into back-office application data more effortlessly, there’s tremendous potential for these tools to add business value.
That said, as we saw with DataGPT, large language models are not flawless and require some creativity to achieve the desired outcome. Therefore, they should not be solely relied upon for all use cases, especially those that demand 100% accuracy.
It’s clear that AI has changed the game. The traditional notion of an application, its operation, and the investment needed to provide top-notch user experiences has been upended, and the speed by which it will continue to change will be unprecedented. Forward-thinking organizations who embrace the possibilities of AI will have a head start on unlocking new strategic value, and won’t risk falling behind.