

Joe Truncale August 15, 2019
What is an operator?
A Kubernetes Operator is an application-specific controller that manages complex application lifecycles on Kubernetes. Operators were introduced into the Kubernetes vocabulary back in 2016, when CoreOS coined the term from SRE cluster operators who were using domain-specific expertise to maintain their more sophisticated applications. Kubernetes Operators have since evolved into a standardized construct meant to codify and automate any application-specific constraints.
“As an example, the etcd operator provides an etcd cluster as a first-class object. Gone are the days of deploying an etcd cluster using a complicated collection of stateful sets, crds, services, and init containers to manage bootstrapping and lifecycle management, et cetera.” – Richard Laub, staff cloud engineer at Nebulaworks
From Etcd to Kafka and Spinnaker, many complex applications have switched over to using their own operators. Prometheus, for example, is a commonly used operator that scrapes metrics endpoints from a variety of services. Prometheus can also run with standard Kubernetes resources, but there are a few differences. The target endpoints that Prometheus scrapes are normally defined in a prometheus.yml which is mounted as a configmap within Kubernetes. Without an operator, if you wanted to add an endpoint you would have to edit that configmap within the cluster. At that point, a sidecar watching that configmap would pick up the change and reload Prometheus. When using the Prometheus operator, you would create a new ServiceMonitor for a new target endpoint. This ServiceMonitor is a Custom Resource Definition (CRD) that the operator is constantly watching and able to reload into Prometheus. This is a much cleaner and declarative approach to managing the config.
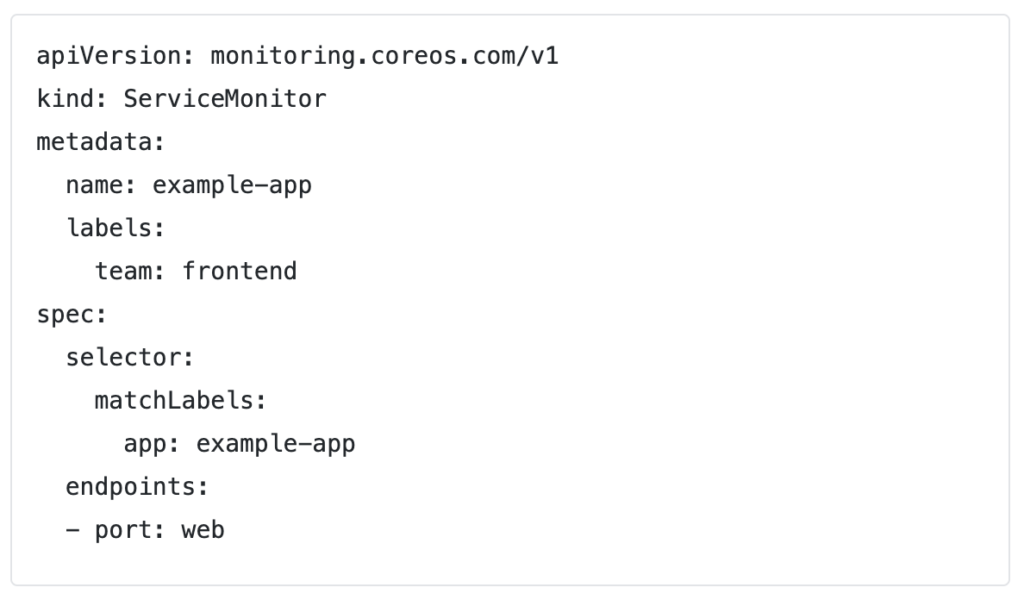
Figure 1: An example of a ServiceMonitor CRD consumed by the Prometheus Operator
When should you use an operator?
You graduated from your single pod manifest into a world of multi-resource deployments. Each one of those simple deployments has now become complex. With services, ingresses, secrets, configmaps, and more, it’s become difficult to manage. You’ve decided to template out those resources using the templating engine of your choice. Now you can use your existing generic resources to support separate environments and configurations. This is all great! Your application has evolved. But what happens when things get even more complicated? That’s where Kubernetes operators come in.
“Without Operators, many applications need intervention to deploy, scale, reconfigure, upgrade, or recover from faults” –Jeremy Thompson CTO at Solodev
If your application requires any manual intervention to perform one of the “cloud native” functions listed above, then it may be a good candidate for an operator. For example, the Kafka operator is able to scale the number of brokers and then rebalance the partitions across consumers. A normal Kubernetes deployment wouldn’t have the concept of rebalancing during Kubernetes native scaling. Operators are designed to reconcile state. As a developer, you can define what the target state looks like, as well as how the operator will go about reconciling the current state to match.

Figure 2: A simplified flow of the Kubernetes operator pattern
We’ve had experience with clients who require Kubernetes resources to perform in a way that is not currently supported by the platform. A simple example would be using Kubernetes cronjobs with the expectation that they support time zones, just as seen in the unix cron spec. Unfortunately, Kubernetes does not currently support time zones as a part of their native cronjobs. This shortcoming has spawned different types of workarounds and hacks that manage to satisfy the business logic. The Kubernetes community has realized that these types of requirements occur more often than not which spawned extensibility in the form of the operator pattern. One such operator designed to solve this problem is Cronjobber by hiddeco, a developer at Weaveworks. The custom resource definition “TZCronJob” allows for additional details in the spec including the timezone. The timezone is then accessible to the operator, which utilises tzdata to consume and schedule it. The controller will then run the specified container image at the appropriate time in the correct timezone.

Figure 3: An example TZCronjob CRD used by Cronjobber
A few caveats
Though operators can help solve our immediate problems, this can quickly become an unsustainable pattern. By introducing these external dependencies on operator frameworks and custom operators, you can end up with unmaintained Kubernetes code that is deeply intertwined with your own implementation. Additionally, the release schedule of operator frameworks and the downstream implementations can lag by an entire Kubernetes release or more. This can prove to be a barrier to upgrading. And lastly, we find that users have a propensity to overcomplicate operator functionality. Feature parity in itself can be complicated, so adding additional features to the operator itself may deserve a separate endeavor.
As with any tooling choices, it’s important to weigh the features against any current or future operational overhead. We’re hopeful that the companies behind these operators will treat them as first-class products and keep them updated. If they’re properly maintained, we have no doubt that operators will continue to bridge the gap between specialized applications and generic Kubernetes.
To find more community-maintained and supported Kubernetes Operators, check OperatorHub.
Have you noticed any manual processes when running your application on Kubernetes that might pose as opportunities to create an Operator?