

Practical Advice For Your GenAI Chatbot
Practical Advice For Your GenAI Chatbot

Alberto Antenangeli
Alberto Antenangeli November 15, 2023
Organizations are embracing the potential of chatbots to reshape user experiences, from the most straightforward conversational support to sophisticated consultative interactions (and beyond). With the technology still in its infancy, there’s a lot to learn about how to develop and refine GenAI chatbots – and that means some trial and error.
In this post, I’ll share some practical learnings about data, resiliency, and generating quality responses that we’ve uncovered when creating chatbots for our clients.
Data Is Everything
Your chatbot will be only as good as the data you provide it; the significance of clean, accessible, and current data should never be underestimated. You need to have a clear understanding of the data’s source, format, and volatility before you begin training the AI.
Source
Understanding where your data comes from, and how you can access it, is fundamental. You’ll need to consider:
- What mechanism you will use to access the data.
- How you can identify the full set of data you need to process.
- How efficiently you can access the data.
Data can come from many different sources, such as documents in shared storage, or blob data from a database. For example, your data may be in the form of documents spread across multiple shared directories. Do you know what those directories are? Do you need to recurse through those directories to access the full data set? What kind of authentication/authorization exists? All of those questions have an impact on how you retrieve the data you need.
Format
The format of your data (simple text, HTML, PDF documents, etc.) makes a big difference in the choices you make around cleansing and metadata enrichment.
While formatting can be valuable (or crucial) for human understanding, that’s usually not the case for AI; most of the time, it’s just noise. That noise comes with a cost, in the form of unnecessary tokens consumed for each document. That’s why it’s important to cleanse unnecessary formatting and repeated information. A great example is headers and footers in HTML pages, which are often highly duplicative; if they don’t add value, they should be removed.
Having said that, some formatting may provide helpful metadata that you can use to enrich the model. We’ve found that titles, subtitles, easily-retrievable document summaries, and select HTML tags (like <summary> or <details>) can add a lot of value.
TIP: Depending on the nature of your data, it may include personally identifiable information (PII). If so, we recommend anonymizing those fields as part of your cleansing process, before training your model.
Our advice on this topic? Resist the temptation to sacrifice quality for quick results – convert your data to plain text before using it.
Volatility
Knowing how often you need to process data is key to keeping your AI up-to-date. That means it’s important to consider how often your data changes.
If the answer is “frequently,” then other considerations come into play. For instance, the time required to access and process the data becomes a critical factor. Crawling web pages, particularly those with complex code and dynamic content, can be time-consuming. Multiply that by a large number of pages, and this process may take several hours to complete. When designing your chatbot, consider whether you need to parallelize this process, or support restartability.
Volatility accounts for all kinds of changes, including deletion or removal of data. Make sure to consider how you’ll handle removing deleted data from your AI. Typically, this requires a reconciliation process that can match the two sets of information to keep them in sync.
Make Your Data Findable
It’s not enough for your data to be in a consumable state – it needs to be findable by your AI, too. This is where your index comes in. There are a few aspects you should take into account when designing your index: search type, index metadata, and partitioning.
The first of these is the kind of search you are planning to perform. Broadly speaking, you have several options:
- Keyword: fast query parsing and matching over searchable fields.
- Semantic: improves on keyword search, by using a re-ranker to understand the semantic meaning of query terms.
- Vector search: search on the vector embeddings of the content.
- Hybrid search: a combination of semantic/keyword & vector search.
From our experience, the hybrid search tends to produce better results. Because it combines both semantic and vector searches when querying the index, this approach handles synonyms and related concepts better. For example, if your training data has information about lessons, but the user asks a question about course offerings, the hybrid approach is much more likely to provide a quality response than using semantic or vector searches alone.
Next, you’ll need to consider the metadata associated with the index. For example:
- The title associated with the document.
- A summary, if it exists.
- If you are crawling from a website, the URL where the document came from. It’s useful to create links to the content as part of the chatbot’s response.
- A unique ID, which could be derived from the metadata. In our case, we hashed the URL to produce a unique ID.
- A timestamp indicating when the page was last updated.
Note: If you choose to use vector search (or a hybrid), you must create embeddings when updating the index; this includes corresponding embeddings for searchable content.
Finally, you’ll need to consider how you partition large content across multiple documents. The recommended best practice is to use 512 tokens per page, with a 25% overlap.
Partitioning not only improves the quality of the results, but also reduces the token utilization if your source documents are fairly large. It is worth stressing again: this is not an exact science. You should always test to find out what is best for your unique use case. As a general rule, pick the lowest overlap percentage that still yields complete responses to your questions.
Generate The Best Responses, Every Time
Prompt Engineering
Anytime you’re working with generative AI, prompt engineering is a key to your success. Building a chatbot is no different.
A good system prompt is essential to ground the behavior of the LLM. Unfortunately, though, there is not a well-defined recipe for creating a good system prompt; it is a substantial amount of trial, error, and refinement.
First, make sure you fully understand your personas. For example:
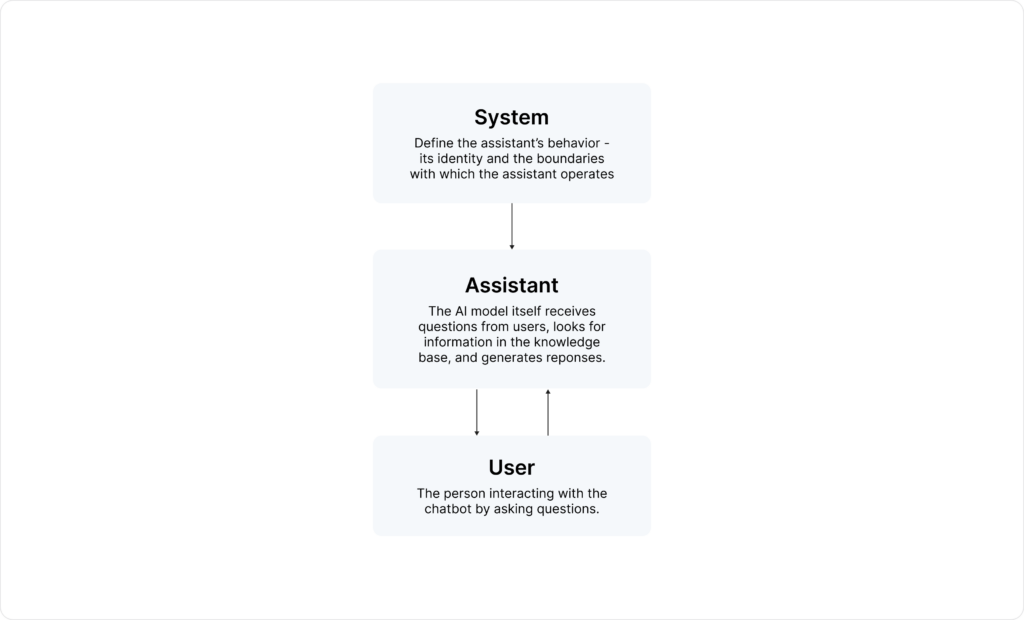
When creating the system prompt, keep in mind these best practices:
- Be precise. When crafting a system prompt, pretend you are giving instructions to a young child who will take them very literally. If you aren’t explicit about a behavior or response, then you will get unpredictable results – which often translates into a poor user experience.
- Define the assistant’s persona. Use the first message in the system prompt to do this; we found “You are an AI assistant that helps users <perform a task> based on <source of the information>” to be effective.
- Contain jailbreaking. Early in your system prompt, make sure to include instructions that define the boundaries of the conversation. For example, “You must answer the question only using the information contained in the retrieved documents” and “You must only answer questions related to <the chatbot domain>”.
- Consider enforcing a “refusal rule.” Depending on your use case, you may want to create a guardrail against inappropriate conversations and responses; for example, “Refuse to answer questions if the answer is not contained in the documents and if the question does not pertain to <the chatbot domain>”.
- Build use case-specific rules. Your system prompts should create and enforce chatbot behaviors that align with your use case and your users’ needs. For example, what to do when there is a multi-part question, how to politely refuse to answer a question, etc.
- Make it conversational. The chatbot will be conversing with a person, so you must account for typical conversational behavior. If you don’t instruct the chatbot on how to answer when the user says “thank you,” its response will be unpredictable. Depending on how stringent your instructions are, your chatbot may respond to a polite interaction with “I don’t have information related to this.”
As you craft your system prompt, remember that the length of the prompt matters just as much as the precision of the instructions. Extremely long system prompts can confuse the LLM, and you may notice some quality degradation when you add too many instructions to the system prompt. It’s important to find the right balance between precision and complexity.
One way to work around this limitation is to create a second prompt, which contains additional, more fine-grained and specific instructions. This second prompt, along with the system prompt, should be inserted between the chat history and the last question asked by the user, like this:

We noticed better behavior when we followed this approach.
Again, this is not an exact science. Engineering the system prompt (and the additional instructions, if you choose to use this approach) takes time and a substantial amount of testing and tuning.
Temperature
The “temperature” of the AI model controls the variety of responses the AI can generate – where a lower temperature will deliver less creative responses, and a higher temperature will deliver more creative ones. For example, if you want repeatable answers, set the temperature to zero. That said, even at zero, there will still be a level of variability.
Keep Your Chatbot On – Always
Resiliency is often top-of-mind when designing any system. After all, one of the biggest benefits of a chatbot is that it’s available to answer questions 24/7.
One approach is to deploy the LLM and the corresponding embedding service across three different regions. When the application receives a question from the user, it randomizes the list of endpoints and, depending on the nature of the error returned, you can go down the randomized list of endpoints and retry the call. While it is possible to implement this by adding more infrastructure, this approach is simple and easy to implement, and it gives finer control over how to handle errors and timeouts.
If your use case calls for supporting a large number of users, but you still would like to use a pay-as-you-go service, you should consider this option.
And finally, proper logging and alerting are of fundamental importance, so you can be assured that the system is functioning as it should.
The Potential of GenAI Chatbots
Implementing an LLM-based chatbot holds great potential for enhancing and streamlining users’ experience. We’ve learned first-hand how this powerful technology can dramatically change knowledge access – and we’ve also learned how, with the right practical guidance and an openness to trial and error, they can be relatively easy to implement in just a few weeks.
This technology is new, and there is no definitive playbook or set of answers yet; using it requires experimentation and creative thinking. Throughout this post, we have explored considerations, best practices, and lessons learned that we hope will guide you in your own journey.