

Modeling & Analyzing Lambda vs. Fargate Breakeven
Modeling & Analyzing Lambda vs. Fargate Breakeven

Sinclair Schuller
Sinclair Schuller October 10, 2019
Part of our job in helping clients design their platform architecture is guiding them in what patterns and technologies to use. Nuvalence’s Linda Navarette wrote a great post on the cost-effectiveness of deploying spring boot in Lambda. I often have more generalized versions of the conversation she focused on in her post. It usually starts with a discussion about whether some part of the architecture should be implemented using serverless or as a microservice running in a container. In many cases, the use case makes the answer clear.
Let’s start with serverless. Serverless naturally aligns with event-based models (i.e. models where you’re often waiting on external systems or results to execute logic versus systems where there is an explicit human invocation of logic).
Most cloud providers orchestrate a call to a serverless function of your choosing when an event happens in any of their systems (e.g. a file is changed in S3, a message being added to a queue). In these cases, the overhead of using a container to encapsulate logic to respond to these events is flat-out more cumbersome, less integrated, and less flexible than using serverless. On the other hand, if you’re building a REST API with meaningful code surface area, stitching together dozens of discrete, independent Lambdas behind a gateway may prove more complex than building a microservice in a container. There are some circumstances, however, where cost is the deciding factor.
As an example, let’s assume we have an application for in-taking and processing tax returns. This application likely experiences tremendous load from January through April that significantly tapers off after April. To handle this, I could create microservices in containers and spin up the necessary number of instances during peak periods, and wind them down to a single instance for the rest of the year. Or I could write the core app logic as Lambdas are activated only as needed. If we look at the cost of these two approaches averaged by month over the course of a year (where the averaging is used to smooth away the peak season and distribute cost over the year), I’d find that there is a breakeven where one becomes cheaper than the other.
This breakeven exists because of cost differences and cost model differences. Serverless functions are paid for in a more granular way: memory over a call duration plus (optionally) fees associated with proxying a public HTTP call to a function over a gateway. Containers are paid for so long as they’re running, regardless of whether they’re servicing calls or not. In our tax app example, I might pay for Lambdas heavily in Q1 of every year, with occasional Lambda activation for people processing their taxes late (paying nothing when not in use). For containers, I’d pay for more instances in Q1, but they might be more cost-effective during that period when compared to Lambda, but I’d have to always pay for at least one instance to accept those late tax returns.
This generally implies that serverless can be cheaper so long as call density remains sparse. While that intuition makes sense, I thought it would be important to model this breakeven situation(in this Google Sheet). In building a breakeven analysis model, it was important to first identify which technologies were necessary to take into account.
For this exercise, the focus was on AWS Lambda (with and without API Gateway) and AWS Fargate (with and without NLB). One important caveat is that this is all about hard dollar savings: containers require additional effort to secure, monitor, and manage when compared to Lambda. This implies a higher management and maintenance cost that is not accounted for in this analysis. Once technologies were identified, defining independent variables that would impact cost became critical:
- Configuration of the proposed Fargate container or Lambda (memory, VCPUs, etc.)
- Average call duration (i.e. how long logic would execute for, on average)
- The average size of the payload being sent to the compute target (this was critical for NLB pricing)
- Average memory required to execute the logic in question
- Per call memory overhead (for libraries, container overhead, etc.)
- Whether or not gateways or load balancers need to be used
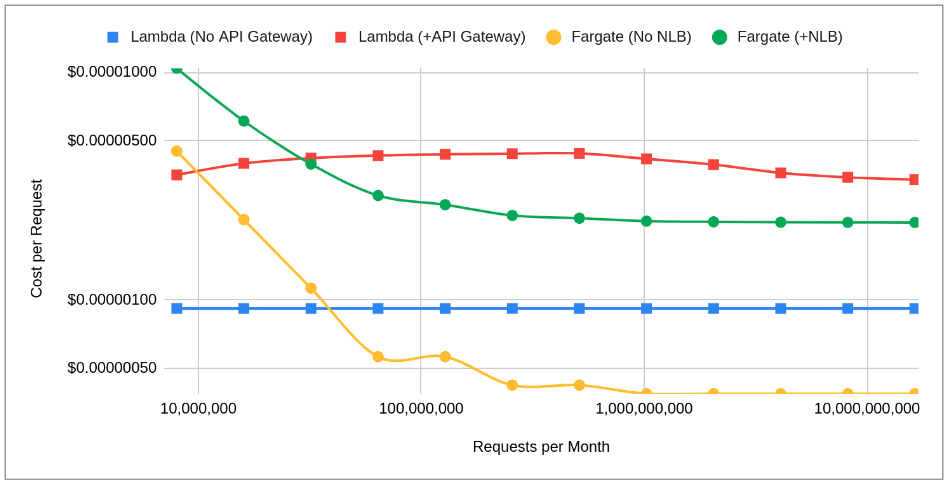
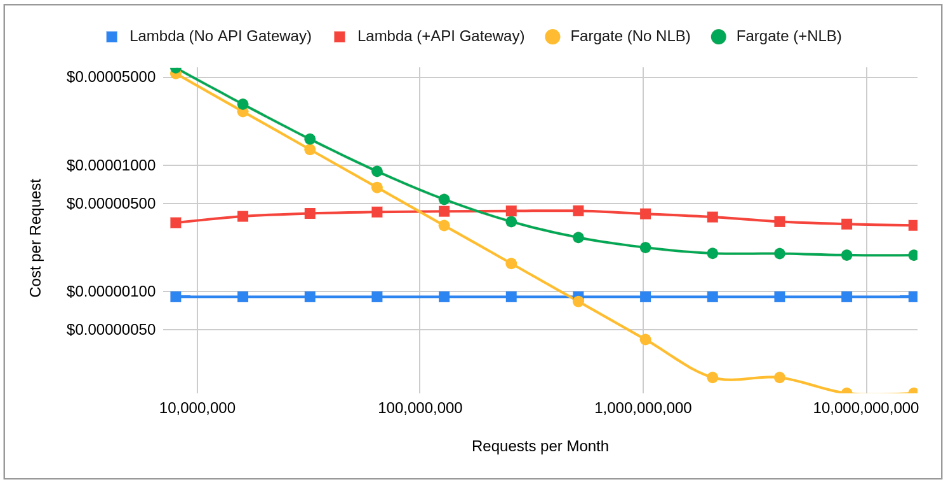
These are the factors that will most greatly influence breakeven. When modeling breakeven, the goal was to generate curves for each of four combinations – Lambda with and without API Gateway and Fargate with and without NLB – and identify intersections. By doing this, we could answer the most important question: given changes in the aforementioned independent variables, could we identify breakeven points that would help clarify when to use which compute model? Given AWS’ public pricing, I ran a few different scenarios to see how points of intersection are influenced by these independent variables.
As a practical matter, I’ll focus primarily on Lambda via API Gateway and Fargate with NLB given that this represents what would be a likely configuration for any public facing APIs: Fargate Config 1: 0.5 CPU, 1GB of Memory, Lambda: 576MB configuration Request: Duration – 100ms, Request Size – 0.3MB, Memory – 500MB, Overhead – 64MBIn this scenario, Lambda (red) is the lower cost option (for the sake of clarity, note that I amortize the free tier into the cost) until we hit about 14.5M requests per month (the logarithmic scale throws off the visual breakeven), leading to a breakeven of $0.00000418 per request. Fargate (green) gets cheaper with an asymptote around $0.0000022 per request.
But what happens if we use a larger container configuration? Fargate Config 4: 4.0 CPU, 30GB of Memory, Lambda: 576MB configuration Request: Duration – 100ms, Request Size – 0.3MB, Memory – 500MB, Overhead – 64MBNow breakeven pushes out to 90M requests per month at $0.00000438 per request, with Fargate per request costs reaching a lower at scale cost asymptote: $0.00000196 per request (about 11% cheaper than with the smaller container configuration).
Breakeven pushes out because larger containers represent a more significant overallocation of resources and cost for small load profiles, but are more economical at scale. These scenarios are driven by modifying container configuration as the model variable. What if we modify the profile of a request instead and choose a fixed container configuration? I used the model to calculate breakeven (through brute force, iterative testing of values) in 3 different scenarios: Varying Request Duration (other parameters remain fixed)
-
Varying Memory used to Process a Request (other parameters remain fixed)
-
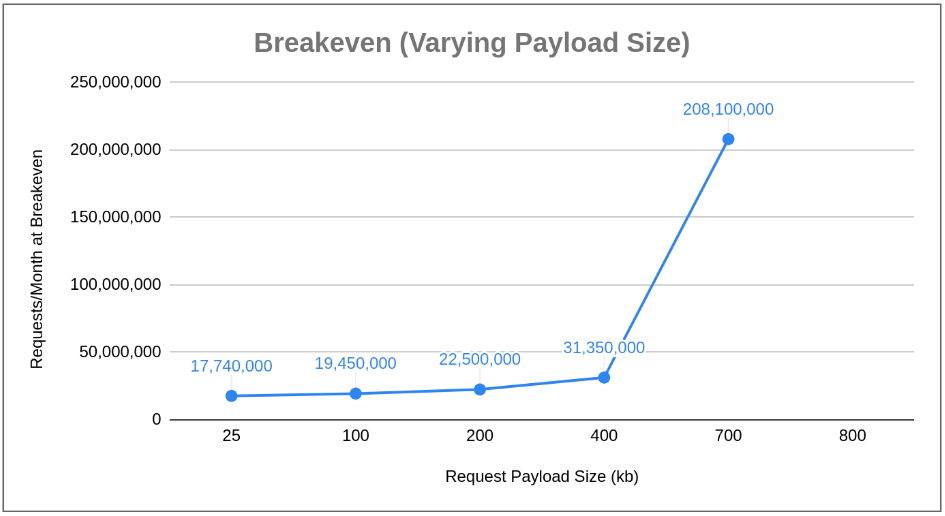
Varying Payload Size (other parameters remain fixed)
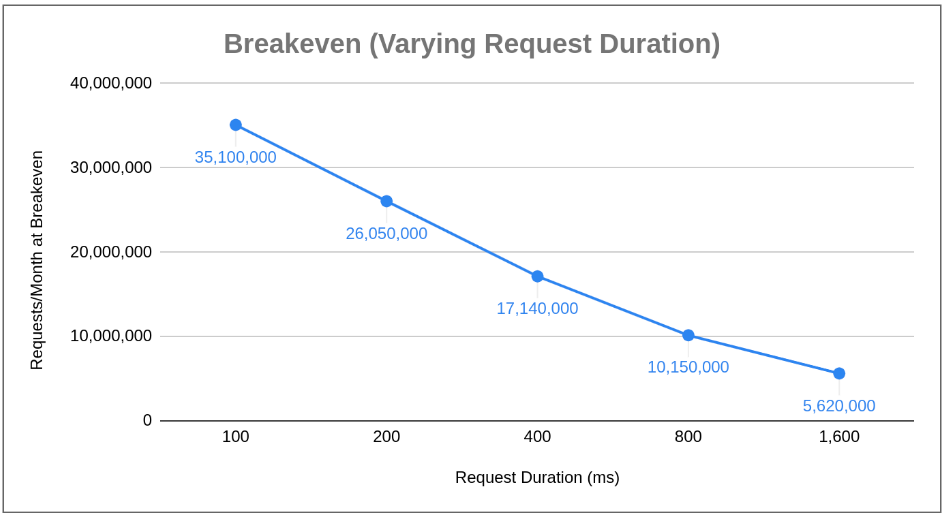
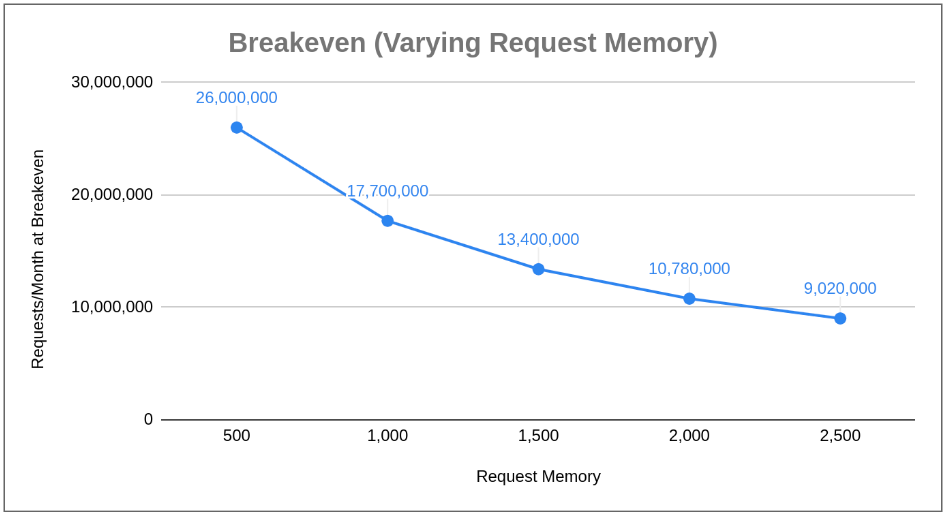
You’ll find the data points for these 3 scenarios in the sheet “Breakeven Summary.” One important note in reading the upcoming charts is that Lambda with API Gateway is always cheaper than Fargate plus NLB to start. This implies that breakeven defines the crossover point where Fargate gets cheaper; that is, any chart showing a decreasing slope shows Fargate getting cheaper more quickly, and any increasing slope shows Fargate getting more expensive relative to Lambda.
Let’s start with varying request duration: What we can conclude is that as the duration of processing a request goes up, Fargate economically outperforms. While the conclusion seems obvious when considering that Lambda costs increase the longer a Lambda executes, it was important to model to understand (a) whether adding NLB charges impacted this observation and (b) at what level is it still preferred to use Lambda over Fargate.
Next, let’s vary memory required to process a request:Similar to request duration, and as a result of Lambda pricing models that increase as Lambda memory requirements increase, we see Fargate getting cheaper as monthly request count averages increase. What we’ve learned in these two cases is as we profile our compute requirements and expected load over time, price optimizations exist in using Fargate plus NLB as request duration and processing memory increase. What about varying request payload size (e.g. the size of the JSON/data being sent to the compute unit)?In this case, we see something very different: a curve with a positive slope, indicating that breakeven pushes out as we increase payload size; that is, Lambda is cheaper than Fargate plus NLB. What’s even more interesting is that 800kb in payload size, Fargate costs hit an asymptote above Lambda’s cost, ensuring that Lambda will always be cheaper regardless of monthly request count averages (this does change a bit if request duration or memory footprint is high). Why? Because of LCU charges incurred by the NLB related to processed bytes. This leads to some important takeaways:
-
Lambda is nearly always cheaper at moderate scale, but more expensive at scale: In most cases where you’re exposing APIs to the outside world, you’ll likely use Lambdas behind API Gateway or Fargate behind NLB. In these cases, Lambda is nearly always cheaper at low and mid monthly request volumes, but can be 2x to 2.5x as expensive at mid to high monthly request volumes when compared to Fargate. Have good estimates for monthly request volume.
-
Lambda CPU scales with memory: With Lambda, you can’t tune memory and CPU separately. Lambda assigns CPU linearly with memory; that is, larger memory footprints may implicitly lead to faster response times even if not memory bound given that more memory means more CPU. Faster response times mean shorter execution times, which reduces call density. This does lead to a caveat with analysis, however: larger Lambda’s may actual process more quickly than ones that are more right sized, potentially leading to cheaper outcomes.
-
Carefully optimize your container sizing to fit near term and long term cost goals: Smaller containers lead to lower overallocation for smaller monthly request loads, meaning that, on a direct cost basis, they lead to cheaper per request costs despite potentially having many instances. Larger containers lead to higher per request costs than smaller ones at lower levels of scale, but can reduce per request costs at scale. Consider leveraging smaller containers early on and switching to larger ones at scale. Despite being in the scale-out era of cloud, scale-up is a very real (and useful) strategy!
-
Understanding the profile of your requests will influence a cost-based decision: If you’re dealing with short duration, smaller memory footprint requests, Lambda will provide the most viable cost option for executing logic at most levels of scale (with Fargate outperforming at large scale). If you have large incoming payload sizes (e.g. files, images, etc.) you might find that NLB costs make using Fargate far too expensive, giving Lambda a cost advantage.
-
Consider using Lambda without API Gateway:One of the ways to take advantage of Lambda at larger scale levels is to do so without using API Gateway (by invoking them through the AWS SDK). This implies a direct call to Lambda. If you aren’t using rate limits, custom authorizers, etc. this might be a reasonable option, particularly for Lambdas that aren’t servicing clients external your apps architecture.
Like any architecture decision, there are many choices, some more obvious than others. In the case of containers and serverless, this couldn’t be more true. But if architectural ambiguity leads you down a cost analysis rabbit hole, the best thing to do is to model it. Hopefully this post provides you a good starting point. The model is shared here as a view-only Google Sheet. I’d encourage you to open the link and download the Google Sheet.