

Democratizing Data for the AI Era with Microsoft Fabric
Democratizing Data for the AI Era with Microsoft Fabric

Nick Young
Nick Young November 20, 2023
At Nuvalence, we seize any opportunity to try out new offerings, especially those involving generative AI. Launched in May under preview, Microsoft Fabric is a data processing platform, powered by AI, that could significantly simplify management of data pipelines – integral and necessary steps for gathering analytics and insights. If so, this would transform the way digital businesses handle and harness data.
Not only can it augment the efforts of traditional data engineers and scientists, but Fabric also makes data processing more accessible to individuals without a background in data engineering. With its simplicity, Fabric offers a significant advantage as it alleviates the challenges faced by many IT leaders who grapple with prolonged data cleanup projects and the associated costs of hiring expensive data engineers. Additionally, it helps organizations simplify their data infrastructure without limiting them to a single cloud vendor. Moreover, Fabric promises accelerated processing speeds, in addition to unveiling otherwise elusive insights that go beyond the capabilities of other data processing tools.
The two things that will distinguish digital businesses from their competitors lies in how they leverage their data effectively, and how they use AI to quickly derive insights from that data. Businesses that don’t adapt to this way of thinking won’t be able to realize the full potential of their digital strategies – and will be quickly left behind by their competitors. Nuvalence’s platform approach is based on this belief. Fabric’s potential to empower both these differentiators, while also offering flexibility, begs the question: Should you start making the transition to Fabric?
The short answer is maybe, but not yet. In this article, I’ll explain why I’m qualifying this recommendation. But first, we need to understand what Microsoft Fabric is.
Microsoft Fabric and its Components
Fabric is “an all-in-one analytics solution for enterprises” that consists of six core components:
- Data Factory
- Synapse Data Engineering
- Synapse Data Warehousing
- Synapse Data Science
- Synapse Real-Time Analytics
- Power BI
If you are at all experienced with the current Azure analytics offerings, some of these should sound familiar. One of the key benefits Fabric promotes over other analytics tool sets is the unified experience of new and existing offerings. As seen in the diagram below, Fabric is backed by OneLake, which acts as a logical data lake for all necessary analytics data. This makes it easier to reuse pre-configured connections, data sources, and transformations across components for analysis, data engineering, or generating reports.

Image credit: Microsoft
In addition, Fabric uses Azure OpenAI Service across all of these components to help customers get the most out of their data.
With this overview in mind, we’re ready to get into the details of my experience using Microsoft Fabric.
The Scenario
I want to transition an on-prem data pipeline to the cloud, with the main purpose of utilizing this data for data analytics and generating reports. The current solution is not platform-centric, as there are a few different methods of data intake (although the source is generally a file, or set of files, placed on an SFTP server). There are also some base enrichments applied, but aside from that, teams will generally take a copy and do as they wish after the data is ingested. We need a solution that can stream data across different source types, and transform and normalize it in a consistent manner, no matter the source. This data should also be in a state that makes it relatively simple to create reports, gather insights, and possibly train machine learning models.
The Experiment
While Fabric is still in public preview as of November 2023, I find it to be an excellent platform for testing the aforementioned scenario. However, before delving deeper into the specifics of my setup, I want to highlight the key evaluators for my experiment:
- Measuring speed is fundamental, and I mean that in more ways than one. Microsoft Fabric should be an accelerator; I shouldn’t need much context to be able to quickly set up any infrastructure or components that I need to be able to quickly provide value from my data. Relatedly, the actual process of moving, transforming, or analyzing data shouldn’t take any longer than if I had used the tools in Azure independently. If it takes twice as long to load from one source to another in Fabric’s Data Factory as it would in the independent offering in Azure, that would be a concern.
- The maturity of the platform is being tested as well. As mentioned, Fabric is still in public preview, but in light of the Fabric Roadmap recently shared by Microsoft, it should certainly be mature enough to make an informed evaluation. That is to say, it is understandable that some kinks will need to be ironed out, but the core capabilities of the platform should be fully functional. I know it may seem like common sense, but this basically boils down to its usability.
As part of my experiment, I’m setting up several data sources and importing them into Fabric using Azure Data Factory. The imported data is then analyzed using Azure Synapse Real-Time Analytics and Microsoft Power BI.
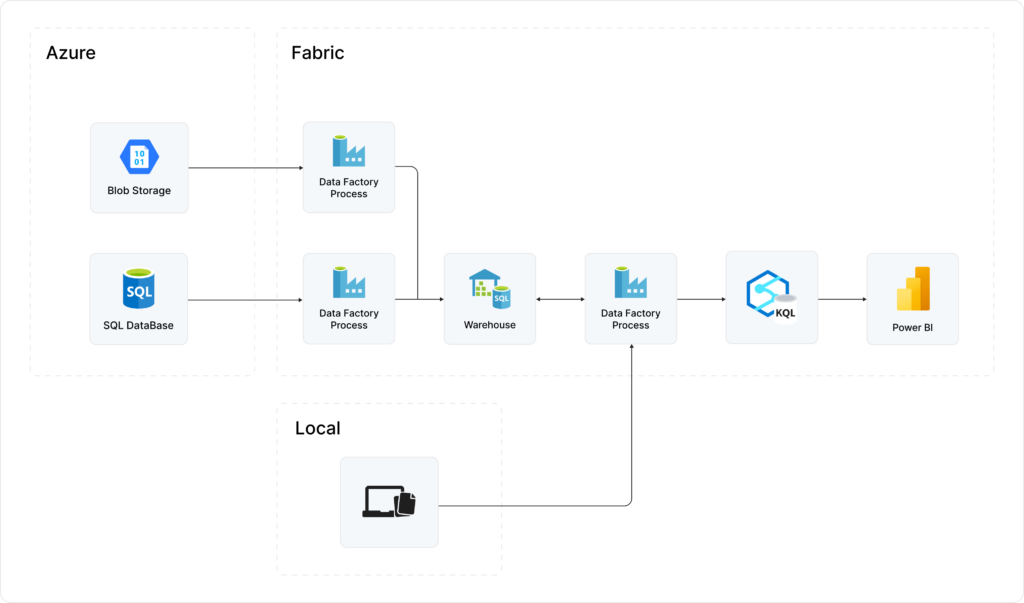
Although it is a relatively simple experiment, this actually represents a real-life scenario that our client currently faces. In this situation, let’s consider a data analyst trying to gather unique insights from multiple sources: two distinct domains, and a locally downloaded report generated by another business unit. Let’s imagine the data sets in these sources break down as follows:
- Domain 1 has all of the hospitals that subscribe to our platform, with data including hospital name, number of employees, and zip.
- Domain 2 has data on costs, e.g., a hospital’s average expenditure on treatment X.
- The generated report has insurance premium rates by zip code, as well as demographic information.
You can imagine all of the insights that you could quickly gather from these three sources. Does spending more on treatment actually lead to better outcomes? Is there a correlation between cost of treatment and demographics? Is there an optimization for the number of residents in a zip code per hospital employee that could result in a shorter length of stay or other desired patient outcome?
Outcomes from our Fabric Platform Experiment
By doing this experiment, I’m able to glean a list of major pros and cons from my experience with Fabric.
Pros of the Fabric Platform
Flexibility
Data Factory has an immense number of connectors from which to pull data. What connectors you can use, and whether or not that connector can be configured as a continuous or one-time load, is dependent on the data source and destination. My experiment uses three sources: an Azure SQL database, a file in Azure Blob Storage, and a local file on my computer (both files were in csv format). As part of the intake process, of course, it’s possible to perform transformations and restructure the data according to your requirements. For the three data sources I’m utilizing, the import process is mostly a one-to-one mapping, albeit with the exclusion of certain columns.
Simplicity
I didn’t need any tutorials before diving in. I refer to the supporting documentation when I feel like I’m running into any issues, but it’s been relatively straightforward to figure out how to get my three sources of data into a warehouse in Data Factory so that they’d be usable by the other components. Assuming there are no complex data transformations, I’d imagine it would not be too complicated for someone, even without a deep technical background, to figure out how to use the components at a high level.
Speed
I’m intentionally dedicating only three days of effort to this experiment, as I feel this should be sufficient to evaluate its efficiency. Based on the size of some of the data I’m importing, these imports are impressively fast. At the least, it’s as fast as if I were using any of the Data Factory tools in Azure independently, which is a key measure for me.
Reasonable Cost
As an engineer, this doesn’t usually occupy my day-to-day concerns (I kid, I kid!). Anyone who cares about value will find a huge win in the potential consolidation of costs for those who are interested in using multiple offerings in Fabric. It allows you to monitor and manage your capacity and assign specific workspaces to that capacity, just as any cloud tool should. When considering cost, it will be helpful to understand the capacities and details of the Fabric pricing model. Your specific costs will obviously depend on how and what you use within Fabric, but a good scale to consider for reference is storage in OneLake is $0.023 per GB per month.
Reusability
One of the core benefits Fabric offers is its integrated, or unified, experience. You can see examples of this when sharing pre-configured connections across workspaces and setting access to the connections to users or groups. Using pre-existing connections is not a new concept, but what is especially convenient in this context is being able to reuse that connection across all of the products that Fabric offers (e.g., using a connection for importing directly into a data warehouse or a Kusto Query Language (KQL) database).
Opportunities for Improvement
Completeness
There are areas where the platform feels a bit incomplete – and understandably so. It’s important to reiterate that Fabric is in public preview; that being said, I did find the experience a little clunky at times. In the default workspace that is set up for users (it’s called “My workspace”), for example, some pre-configured connections are not showing up in the dropdowns when I select a data source for a data load. I am not sure if this workspace is only intended to be used in testing, but I do notice that I’m unable to replicate this issue when creating additional custom workspaces. A hallmark of a good product for me is that it behaves consistently under similar conditions, so this inconsistency is something that I’d like to see improved.
Intuitiveness
Although the core of Fabric is its unified experience, at times it’s not especially intuitive how the tools interact with one another. A natural flow in the UX is invaluable – and expected, especially when targeting a diverse user base with varying levels of technical expertise. Ironically, I think the lines between the components would actually benefit from being blurred a little more. For example, when looking at a data warehouse in Data Factory, an option might be “import data,” whereas in Power BI, the option might be “generate a report.” In this example, I would expect both options to be available regardless of the tool I’m using. I expect this to come naturally as Fabric matures.
More Robust AI Capability
I expect that one of the primary motivations for considering a move to Fabric is the anticipation of AI capabilities. While it’s likely that Fabric is using AI behind the scenes to optimize performance or make suggestions, unfortunately, I didn’t notice a lot of front-end AI capability during my experiment. Anticipated features like Microsoft Copilot, an AI tool that has the ability to produce insights, answer questions you might have about your data, and even generate reports, are still in private preview. Meanwhile, the messaging can be unclear as to what is currently available and when future integrations are expected to be available. Microsoft has released a roadmap that clarifies this somewhat, and specifically calls out a future capability, due Q4 2023, that allows you to write queries in natural language and have them translated into KQL in Synapse Real-Time Analytics.
As of this writing, I have to say that if AI functionality is a primary factor behind your interest in Fabric, you might be disappointed to find its presence somewhat lacking. That being said, if you are looking to run ML experiments and create models from your imported data, Synapse Data Science seamlessly integrates into the experience.
Fabric: An AI Analytics Platform with Potential
Although I would not move to Fabric just yet, I’d certainly recommend giving it a try, especially if you are already using Azure or other Microsoft analytics products. The freedom it offers from having to be locked into a single cloud vendor offers an opportunity to innovate and experiment with new data use cases. Whether or not you eventually end up using Fabric in the future, any data platform that drives positive outcomes makes it vital to the digital businesses of today and tomorrow. Developing skills with these platforms has little downside. Think of Fabric’s upside as the Excel of the future, on steroids.
Fabric undoubtedly holds the potential to revolutionize how we can harness the constantly expanding pool of available data. I intend to delve deeper into the paradigm shift that this platform represents and will follow up this article with any exciting new discoveries.