

Data Mesh on Google Cloud: Achieving Data-Driven Value through Decoupled Domain Modeling
Data Mesh on Google Cloud: Achieving Data-Driven Value through Decoupled Domain Modeling

Daniel Loman
Daniel Loman April 1, 2022
As technology has improved and storage has gotten cheaper, data architecture has evolved greatly over the years. The Data Warehouse model – a large series of relational databases – evolved into Data Lakes, which allows for the storage of unstructured data. Data warehouse and data lake platforms are both large, centralized solutions which store raw data from all kinds of source systems, put it through a bunch of pipelines to clean and transform it, and make it available for end users in the form of reports, dashboards or machine learning models. While data lakes can provide a lot of value to an organization by storing diverse data sources in one place, their monolithic nature can also lead to challenges with complexity and scalability within the data platform.
In 2019 Zhamak Dehghani introduced a new type of data architecture called Data Mesh to address some of the issues encountered with centralized Data Warehouses and Data Lakes. The main idea behind a data mesh framework is to decentralize the data platform so that data products and human resources are broken out into each domain, rather than all in one place. A data mesh reduces the fragility of having one monolithic solution and better handles the complexity that naturally emerges as source data grows and the platform scales.
We have seen too many organizations spend their data engineering resources building an insurmountable number of data pipelines and never reach their data aggregation objectives. They put extra emphasis on metrics such as number of sources and volume of data rather than more precise and actionable outcomes that impact the business like data consumer satisfaction and KPIs. In addition, their data consumers typically find themselves spending most of their time cleaning up data quality and validation concerns.
To be clear, Data Mesh principles do not state “avoid Data Warehouses and Data Lakes at all costs,” but rather utilize them within the context of a domain to merge and blend data sets together to support a higher-level conclusion. This post is about how to make use of Data Warehousing solutions like Google BigQuery even in the context of a Mesh.
Evolving from Data Lakes to a Data Mesh
According to Dehghani, a data platform generally aims to accomplish three things at a high level: Ingesting, Processing, and Serving data. In a traditional data warehouse/data lake architecture, the model design might look like this:
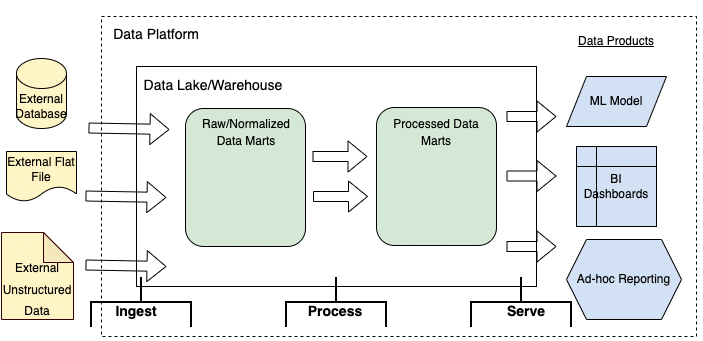
Figure 1: A generic Data Warehouse/Data Lake architecture diagram
In the model shown in Figure 1, data is first ingested from external source systems into the data lake. Within the data lake data is cleaned, processed and aggregated to put in a more usable format for data scientists to serve to the customer in the form of a machine learning model or BI dashboard.
In practice, there may be a team of data engineers responsible for all of the data ingestion and ETL into the data lake, where data architects and data scientists clean and process the data and build their own pipelines for aggregated data marts. Machine learning engineers and BI specialists focus on building ML models and dashboards from the cleaned data for all business domains. As a result, governance of the data platform is siloed vertically, where teams of specialists focus on what they do best without seeing the full lifecycle of the data.

Figure 2: A Data Warehouse/Data Lake architecture diagram, siloed by technical domain
This leads to the challenges Dehghani illustrated in her paper: Siloed data ownership, unnecessary complexity and challenges with scalability. In a centralized data lake, domain data ownership is often sacrificed for the larger goal of building one monolithic entity. Data engineers and scientists may focus primarily on building generalized pipelines and models across all domains, and lose focus on domain-specific expertise. Data pipelines can get entangled across domains and become increasingly convoluted as more data sources are added, and there is a high risk of duplication as multiple engineers transform the same source data. The added complexity makes the entire data platform fragile; a seemingly small bug early in the pipeline can have massive downstream impacts. Of course, those issues compound as the data platform gathers more data sources, which makes scaling the platform a lot more difficult than simply bringing more data into the data lake. From an outcomes perspective, these challenges make deriving insights from data take longer and of lower quality.
The decentralized approach of a data mesh architecture aims to solve these problems not necessarily with novel technology, but with a new paradigm of data governance. Consider this circular model of data governance:
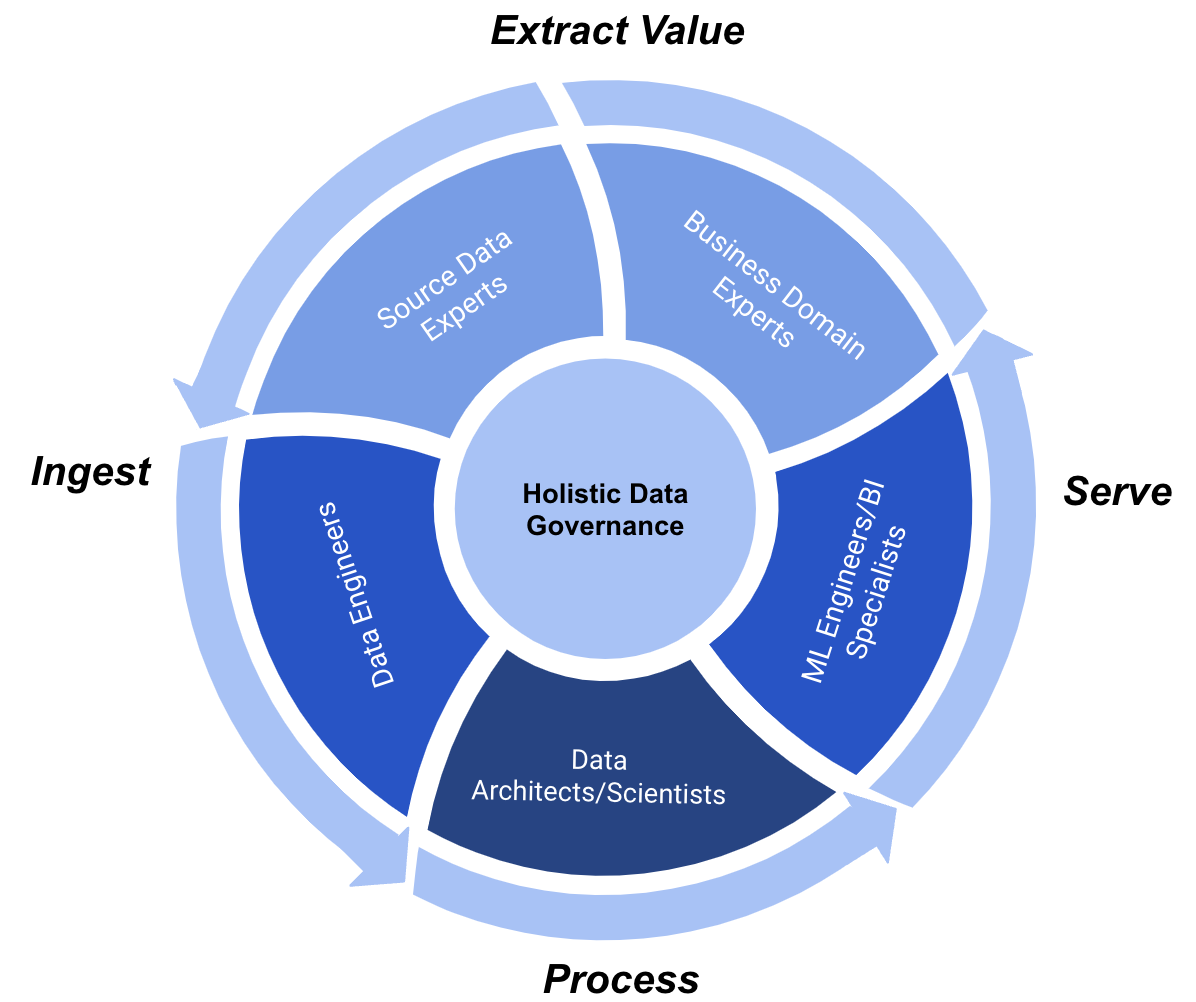
Figure 3: A Circular Model of Data Governance
In this design, technical and business expertise are intertwined. Data engineers sit adjacent to source data experts, which means engineers must deeply understand the nature of the source data they’re ingesting. Those engineers also work next to the data architects, so processing and transforming data can’t be done without also knowing where it came from. Data scientists and ML engineers work closely with business experts, enabling rapid feedback and meaningful understanding of the business impact of their models. And on the flipside, domain and business experts must understand at some level how their data is being ingested, processed and served back to them. In this sense, data truly comes “full circle”.
Evolving from a data lake architecture means thinking of data holistically as a product, and structuring resources in a way to enable that. A data mesh platform accomplishes this by siloing the data platform by business domain, not technical specialty. Such a design would split the platform horizontally, rather than vertically like with the centralized data lake:

Figure 4: A Data Mesh architecture diagram siloed by domain
It’s important to note that in a data mesh platform, the specific elements in Figure 4 are simply nodes on the mesh. It is also likely that multiple data sources constitute one domain. While having a data lake might still be convenient for the data team as a place to build data transformations and query processed data from, a data mesh is geared for rapid insights – so it may make more sense for machine learning engineers to build models directly from source system APIs, or to use a document database for storage instead of a relational one. But the main idea is that data ownership is at the domain level, by a cross-functional team who deeply understands the data and the business value it provides.
Pipelines in a data mesh are decoupled from disparate domains, so there is a lower order of complexity within the data platform. In contrast to the fragile nature of a monolithic data lake, with proper governance a data mesh architecture can actually become antifragile: because data products are separated by domain, they can fail independently without sinking the larger data platform – and potentially make it stronger as a whole by learning from those failings. Likewise, the data platform can learn and implement best practices from its most successful data products.
Data Mesh on Google Cloud Platform
Implementing a data mesh architecture at your organization requires strong discipline and data governance more so than leveraging a specific technology or toolset. Google Cloud Platform naturally lends itself to this type of architecture design.
Consider a simple Google Cloud data platform where Cloud Storage is used as the data lake, BigQuery is the analytics data warehouse, and data transformation pipelines are built through Cloud Composer. As Dehghani notes, a data mesh is fundamentally built from independently deployable but functionally cohesive architectural quanta. In GCP, it’s very easy to visualize components of different services as architectural quanta; In this example, buckets in Cloud Storage, projects in BigQuery and environments in Cloud Composer:
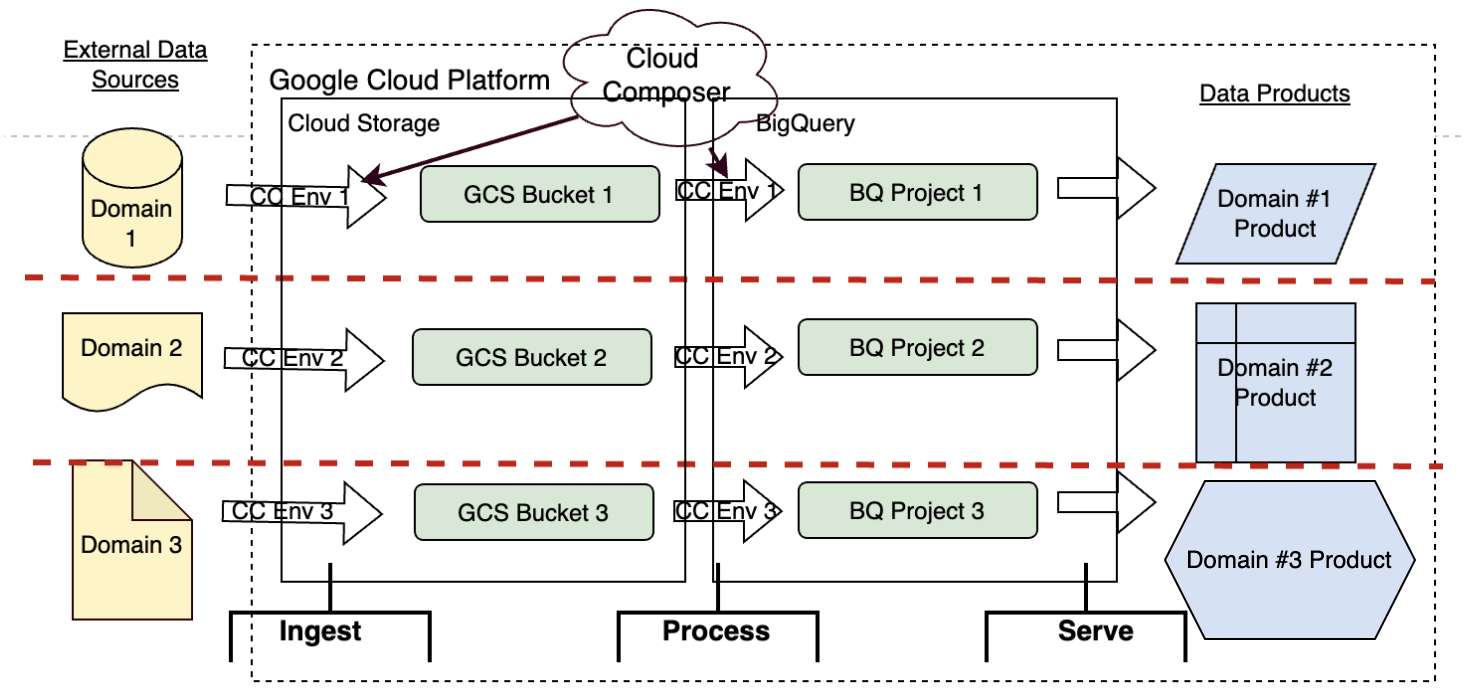
Figure 5: A generic Data Mesh architecture diagram on Google Cloud Platform
Access and permissions for all of these architectural quanta would be managed via GCP’s Identity and Access Management (IAM) service, so it would be logical to create cross-functional groups for each domain which are given access to only architectural quanta within their domain. From the standpoint of the user in a group, they would be building on domain-specific architecture that is completely independent from other domains, which makes the system decentralized from a top-down view.
That’s not to imply that a data mesh is simply a distributed series of data lakes and warehouses. While BigQuery is an excellent analytics solution and may make the most sense for a particular domain or use case, it can also be the proverbial nail to the hammer of an organization that views their data platform strictly through the lens of a data warehouse. Depending on the domain and nature of the source data, there are many other approaches that Google Cloud Platform supports that may be more appropriate.
Consider a hospital system that collects data for just about everything in the organization: A team in the finance domain might be interested in collecting data from multiple billing systems, storing it in a warehouse, and building dashboards to trend expenses and revenue over time. A clinical team might want to ingest streaming data directly from the electronic health record and run it through a machine learning model to monitor patients for sepsis in real-time. Or maybe a data analyst just needs to run occasional ad-hoc reports out of their scheduling system for an HR manager. For this organization, it wouldn’t make sense to simply dump all of their data into a lake.
In GCP there is a large suite of tools to handle these different use cases. The finance team could use the more traditional data lake/warehouse stack of Cloud Storage and BigQuery. The clinical team could stream application data to a Pub/Sub topic, and then use Cloud Dataflow to process the data in a machine learning pipeline. And if the owners of the scheduling system could write APIs on top of the source system, the analyst could simply pull from those to build their reports. In a data mesh, all of these architectures would fall under the larger umbrella of a Google Cloud Data Platform:

Figure 6: A complex Data Mesh architecture diagram on Google Cloud Platform
Though these domains are decentralized, a data mesh should still have some standardization at the platform scope. Because GCP is hosted by Google, things like infrastructure and resource allocation would be fully managed by them across domains. GCP’s elastic services and autoscaling feature makes it easy to scale the platform, since resources automatically scale in response to demand. In a decentralized environment, this means the platform could scale to any number of domains with their own storage solutions, data pipelines and applications all running in parallel. To top it all, GCP also offers Cloud Catalog, a data management and discovery tool that provides visibility to all data assets in BigQuery and Pub/Sub on the platform.
Finally, GCP is flexible enough to re-centralize data across domains where appropriate. There may be use cases for data across domains to be combined, or for hyper-specialized engineers to focus only on building models from data that’s in BigQuery. This flexibility would also be managed in IAM, where instead of domain-specific user groups you could have technology-specific groups that are managed vertically like in Figure 2. For example in BigQuery, tables from one project can be joined to tables from other projects, so a user with access to multiple BigQuery projects in Figure 5 could build a model or dashboard with data from both. In a data platform built on GCP, an organization wouldn’t have to sacrifice all specialization for decentralization – rather it would be a lever that could be pulled.
If your organization is looking to evolve its data architecture from a data lake to a data mesh, or wants elements of both, Google Cloud Platform is a fantastic solution. There are no barriers to a centralized approach, but an organization can easily operate in a data mesh paradigm by implementing a certain data governance structure and designing their storage architecture and data pipelines in a decentralized manner.