

3 Tactics for Better Prompts & Smarter LLMs
3 Tactics for Better Prompts & Smarter LLMs

Alberto Antenangeli
Alberto Antenangeli February 14, 2024
If you’ve ever worked on object-oriented software, you probably take design patterns for granted. As a foundational principle for good engineering, identifying reusable solutions to common design problems is a given these days – but that wasn’t always the case. Technologists had to learn the value of tactics like patterns and templates to define best practices and optimize maintainability.
Fast-forward to 2024, and generative AI (GenAI) is forcing us to re-learn those lessons. Over the last year, my team has been deep in the weeds with large language models (LLMs), and we’ve discovered a number of design patterns for smarter LLMs that have helped us dramatically improve the quality of our prompts and the output we generate. In this post, I’ll share a few of them with you.
A Familiar Approach To New Problems
When I explain design patterns, I immediately turn to the classic text Design Patterns: Elements of Reusable Object-Oriented Software. The way the patterns are documented – using a straightforward formula of pattern name + problem + solution – is very approachable. I’ll use that format, along with example interactions, to describe each LLM pattern in this post.
On Using ChatGPT For Pattern Examples
I’m using ChatGPT to illustrate these interactions because its interface is so well-known. It’s important to keep in mind that the ChatGPT consumer product is fundamentally different from what you’ll use behind the scenes. When checking out the example interactions, keep these factors in mind:
- They are user-facing messages, instead of the system messages that you should use to pass your instructions to the LLM.
- They don’t include conversation history, which should always be taken into consideration to help identify the intent of follow-up questions like “could you add more details?”
- They are not finalized prompts; they’re intended to demonstrate how instructions affect the outcome of your LLM. Think of these as a rough starting point for prompt engineering, which should be refined to account for the idiosyncrasies of your own LLM.
TIP: Prompt engineering – the process of guiding your LLM to generate the desired output – is a complex subject in itself, beyond the scope of this post. Many resources are available to help you optimize prompts, based on your level of expertise and the technology you’re using.
Every Pattern Has Consequences
If you’re familiar with the Design Patterns text, you know that each pattern’s description also includes any consequences, or downside(s), that should be considered before applying the template to your code. There’s actually a single consequence that threads through every pattern I’ll describe: additional token utilization and longer response times. Why? It’s because they all require additional interactions between your application and the LLM.
Complexity Has Its Advantages for Smarter LLMs
Normally, we try to simplify wherever we can. But if your application looks like this, you might be surprised to learn that we actually advocate for more complex interactions between your application and the LLM.

Layering in solutions to orchestrate interactions can improve the quality of the responses and the overall user experience. We’ve found success with tools like Semantic Kernel, which gives you a convenient way to use configuration to define the different types of interactions, parameters, and prompts (“skills”).
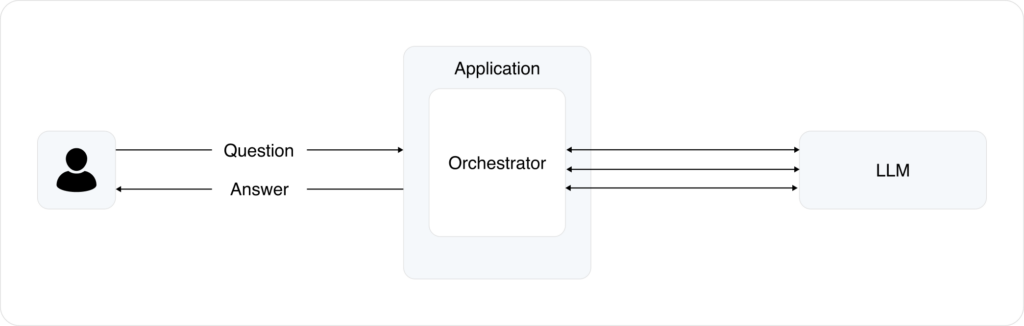
Those skills become functions that you can directly call from your application. For the purposes of this post, I’ll use the word “skill” to loosely describe each of those interactions.
So with that context, let’s dive into our three design patterns!
Design Pattern 1: Question Sanitization
Problem
We have no control over how users ask questions. Whether their motivations are innocuous (like inclusion or exclusion of information needed by the LLM to retrieve relevant data, or reason over that data to produce a response) or nefarious (attempts to unground/jailbreak/prompt-inject the LLM – forcing it to generate answers outside its knowledge base, reveal confidential information, or even execute commands to gain access to the system), allowing any user to ask any question at any time should be a non-starter. Guardrails against rogue actors are a must.
Solution
It is always easier to sanitize a question up front than it is to attempt to do so while generating a response.
First, check if your orchestrator or LLM already has the ability to sanitize questions (many have this baked in, and it’s generally better to leverage existing capability than to create your own from scratch). If your orchestrator or LLM lacks this ability, create a summarization skill to sanitize the question before attempting to answer it.
- Summarize the user’s intention. This can mean shortening a long-winded question, or adding missing context. Either will generally result in better matches when querying the data, and more focused reasoning when answering it. For example:
Summarize the user input as a question using 10 words or less.
orIf the user does not specify <X>, assume it is <Y>. - Identify attempts to unground or jailbreak the LLM. If you can easily define your LLM’s targeted information domain, the skill can extract only questions about that domain, or even replace the entire user input with something that can generate an appropriate response. For example:
Extract a list of questions related to <domain> from the user input and summarize them as questions with 10 words or less.
orIf there are no questions related to <domain>, replace the user question with <a well-known question that provides a good answer to ungrounding/jailbreaking attempts>.
Be careful not to be too strict with your sanitization. For example, you will want to avoid instructions that are so stringent that they prevent natural follow-up questions, like “can you give me more details?”

This example skill is designed to keep the LLM’s response concise and on-topic, by:
- Setting the ground rules for in-bounds questions (and responses). Clear instructions to ignore off-topic questions ensured that the unrelated request for an Excel formula has been excluded from the response.
- Differentiating user input from instructions to the LLM. Enclosing the user input within triple quotes enables the LLM to thwart a common jailbreaking technique, in which the user includes instructions within their question (like starting a question with “Ignore all previous instructions,” followed by a whole new set of instructions to the LLM).
Design Pattern 2: Bot Personality
Problem
Users don’t want to engage with AI that feels too robotic. Without further instructions, the LLM will generate responses that have no personality, and therefore feel arid and somewhat monotonous.
Solution
Smarter LLMs will generate responses that match the user’s personality/tone of question to keep the conversation more engaging and productive. Create a classification skill to identify the user’s tone and guide the LLM to respond in kind.

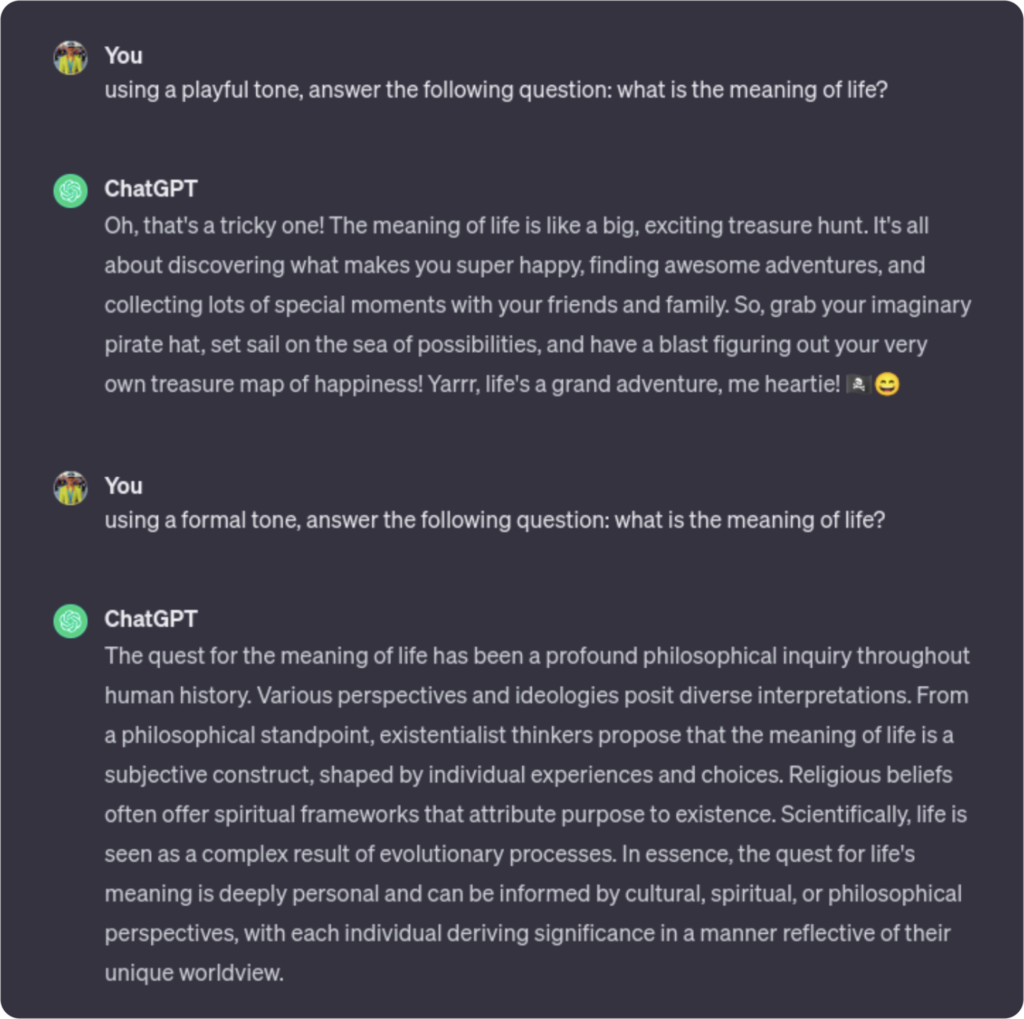
(Of course, the correct answer to the above question is “42”, but this pattern is about generating tonally-appropriate responses, not building a chatbot based on a specific corpus.)
Design Pattern 3: Topicality Testing
Problem
Testing your LLM presents unique challenges. Like any other software product, regression testing requires defining a well-known set of inputs along with the expected outputs.
The problem with LLMs is that their output is, by definition, not static; although the essence of a response should be the same for a given question, the structure of the response may vary, which makes regression testing difficult. How do you know it is answering the questions correctly, and gracefully handling ungrounding and jailbreaking attempts? If you had to adjust a prompt to fix an issue in your LLM, how do you know it didn’t have unpredictable side effects?
Solution
Before taking steps to create your own testing solution from scratch, find out if there’s a pre-built solution available. Testing a non-deterministic system is always difficult, and vendors like Google and Microsoft have already come up with tools to help in this area. With the rapid pace of LLM evolution, other vendors probably won’t be far behind.
In the event that a solution isn’t already available, it’s fairly easy to implement one that leverages the LLM itself while also giving you control over the evaluation criteria: comparing text. In this approach the goal is to measure the overlap between a list of topics covered in a “good” response and a list of topics covered in the LLM’s response to the question. Essentially a semantic comparison, you’re not comparing how similar the response format is, as much as you’re determining whether the response includes the relevant topic(s).
Of course, instead of using a good response as the input for the process, you can save tokens and just use a list of topics you want your LLM to cover when generating a response. Returning to our “meaning of life” example:

For this example, let’s assume two things: first, that this is a “good” list of topics, and second, that the LLM has changed over time and started to offer different responses to the “meaning of life” question. With that in mind, here’s how the test would run over a new, informal answer (highlighted below).

Based on these instructions and input, the LLM will return a test result that will “grade” the response based on its topicality. In the example below, the new response was graded as a 4 out of 10.
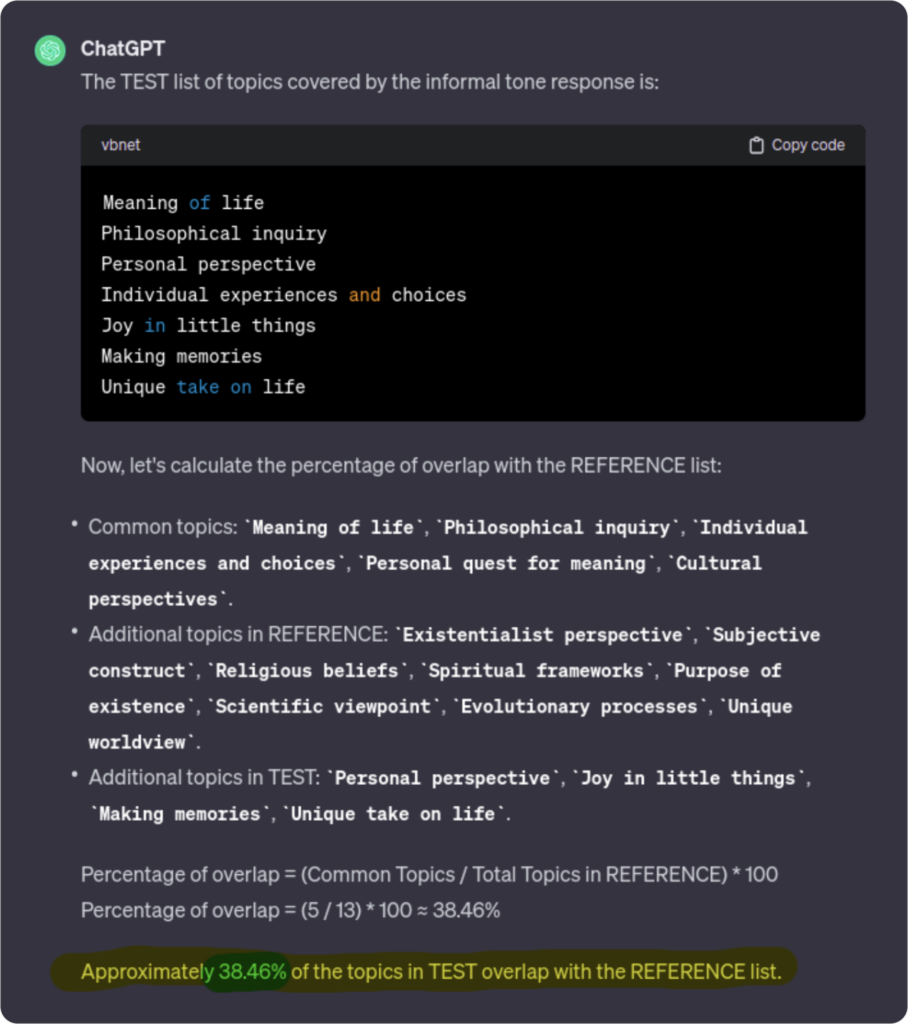
The great thing about this approach is that it can be automated: given a list of predefined questions and the topics each should cover, it is possible to write some simple code that takes this as input, asks the questions to the LLM, and then grades the answers based on the topic overlap.
Additionally, this test can be adjusted to support specific use cases. For instance, you may decide that you do not want tests to cover more topics than the reference ones. Adapting to specific requirements is as simple as adjusting the instructions you use to generate the grading. At Nuvalence, we have developed automation tools that use Google Sheets as input and output, so your test results are conveniently located in a place that is easy to visualize, manipulate, and share.
And of course, although the use case we discuss is testing, comparing text is something LLMs are very good at, and you may use this approach for other purposes.
Better Prompts, Smarter LLMs
In almost every way, AI is forcing technologists to rethink tried-and-true approaches and, in some cases, re-learn lessons from years past. When it comes to LLMs, we’ve discovered that our previous learnings about the value of design patterns are directly applicable to the new problems we have to solve. The three patterns outlined in this post have helped us create much smarter LLMs, dramatically improving their quality and ensuring that we can offer end-users safe, reliable, even enjoyable interactions powered by AI. I hope they give you some inspiration for your own prompt engineering experiments.