

Do GPT-4 Turbo and Custom GPTs Change the AI Game?
Do GPT-4 Turbo and Custom GPTs Change the AI Game?

Alexander Jettel
Alexander Jettel November 13, 2023
ChatGPT has revolutionized the landscape of generative AI, rapidly becoming a cornerstone technology for millions since its debut. Its transformative impact has been celebrated, but that hasn’t come without inherent limitations: small context windows, narrow chatbot applications, and a complex process to embed new knowledge into the model, just to name a few.
That’s why we were thrilled to learn that OpenAI has been listening to their user base – and making some pretty impactful enhancements in response. The recent OpenAI Developer Day showcased a series of these advancements. In this post, we’ll unpack the ones we’re most excited about, and explain why they should matter to you as well.
GPT-4 Turbo: (Mostly) Uniting Speed and Context Scale
GPT-4’s ability to only process around 8,000 tokens/24 pages of text limited its potential for the enterprise and created an opening for competitors like Anthropic’s Claude. That’s all changed with the release of GPT-4 Turbo, which OpenAI is touting as the most powerful GPT yet. But is that the case? Here’s what we found.
Dramatically Improved Capacity (with a Caveat)
OpenAI’s GPT-4 Turbo boasts a 128,000 token window, quadrupling its predecessor’s capacity and matching Anthropic’s Claude 2 and Claude Instant. Our tests suggest GPT-4 Turbo’s performance is on par with (if not superior to) Claude for everyday tasks, such as summarization or sentiment analysis. However, there are signs that GPT-4 Turbo lacks advanced reasoning, as laid out in this blog post.
Significant Potential for Cost Savings
Cost often factors into decisions about which LLM to choose. In terms of pricing, OpenAI’s model is more cost-effective, undercutting Anthropic by $0.00102 per 1,000 input tokens and $0.00268 for outputs.
Depending on your needs, costs may vary widely. For example, JSON documents typically generate a large number of tokens due to the number of brackets and quotation marks. Imagine a scenario where you need to generate a 4,000-token output from a single 100,000-token JSON document. By using OpenAI vs. Anthropic, you would save $0.11 per document. While these savings might not initially appear significant, it’s essential to consider the broader picture. Integrating that JSON file into an automated test result analysis system, running 100 times daily for a month, would result in a remarkable cumulative savings of $338.16. This example illustrates a low-hanging cost-saving opportunity that arises simply by switching from one Language Model provider to the other.
The real cost-saver, though, lies in simplified development. Larger context windows mean businesses can enhance user experience and slash development time, by avoiding the complexity of managing out-of-context data and chunking large inputs. This opens up the possibility of one- or multi-shot priming each request, reducing the need to custom-train models and improving the end-user experience.
Mixed Results For Response Times
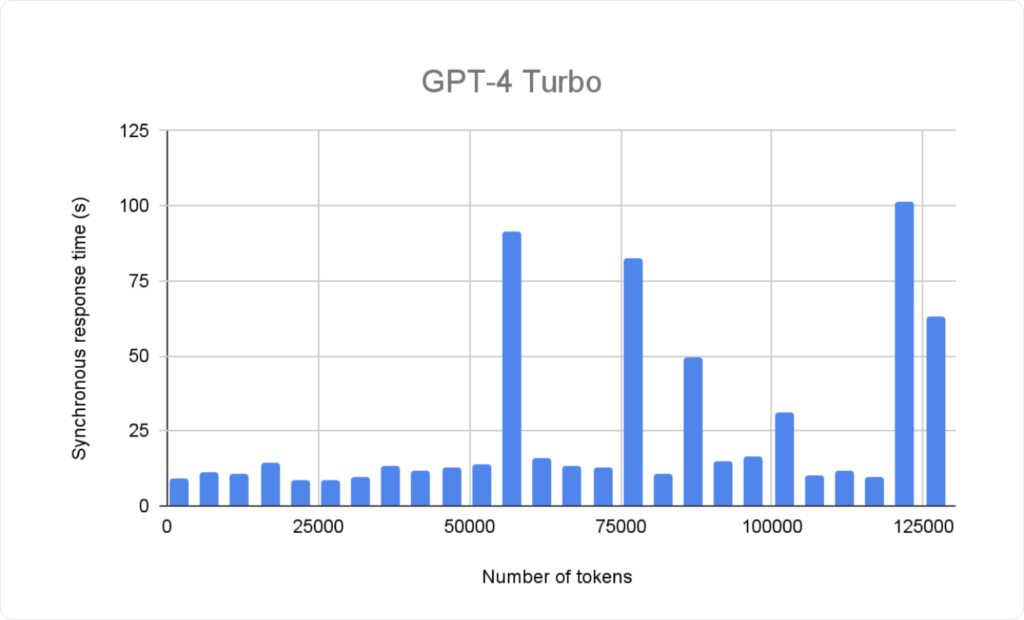
The synchronous response time – the length of time you wait to receive a full response – is an important performance indicator. According to our tests, GPT-4 Turbo (which is currently only available via the API using the gpt-4-1106-preview model) has a 75th percentile of 8-16 seconds. For that reason, we still advise caution when using it.
The good news is that this response time is irrespective of the passed-in context size (up to 128,000 tokens, of course). The bad news is that due to scaling issues on OpenAI’s side, response times can still fluctuate heavily. We have seen response times of over two minutes; though repeating the very same request results in the normal 8-16 second response time.
For asynchronous calls, the same observations hold true. We observed an initial 8-10 second delay before the response started streaming back. Furthermore, we also observed the same response time outlier behavior of certain requests.
In general, GPT-4 Turbo still marks a significant improvement over the previous models, which necessitated multiple API calls for larger contexts, often extending response times to multiple minutes.
As with the previous models, the response times are expected to decrease and the textual quality of the responses is expected to increase as the model is optimized and made available to the public via the ChatGPT interface.
The Customization Wave: Build Your Own GPTs
OpenAI’s previous approach to ChatGPT was very much one-size-fits-all. Customization through special instructions was possible, but somewhat restrictive, and even with the right prompts, the trained conversation remained tethered to your account. What if you could eliminate these hurdles and craft a shareable, personalized GPT? With OpenAI’s new GPTs, that’s a reality – and it doesn’t require engineering expertise to achieve it.
These custom GPTs can be understood as individual versions of ChatGPT, tailored to certain needs with very specific functionalities. Currently accessible through the “My GPTs” section within ChatGPT, the GPT builder is a convenient, user-friendly experience that’s available to ChatGPT users with a Plus or Enterprise account.
GPTs offer a lot of functionality already; here are a few highlights that we’re especially excited about.
- No-code knowledge pre-seeding. When creating a custom GPT, developers — or anyone, thanks to the no-code, chat-style creation tool — can pre-seed the model with knowledge. Even though it works much like a RAG setup or a context-instilled prompt, this approach is unique in that it does not require any coding skills or knowledge of vector databases and RAG modeling.
- One-click conversation starters. The custom GPT can be set up with conversation starters, which can be used to suggest prompts to your GPT’s users, or to bookmark often-used prompts.
- Seamless API integration. The revamped action system allows for seamless integration of any API endpoint, allowing integration of multiple different endpoints into the same custom GPT. For example, social media APIs and online shopping APIs can be combined in one GPT to streamline the purchasing of gifts on birthdays.
- Effortless conversion of plugins to actions. If you already set up ChatGPT plugins, it’s easy to convert them into actions by simply importing them via the existing plugin openapi.yaml file.
Are GPTs Secure?
It’s been widely reported (and well-understood) that the privacy of user-submitted data to OpenAI using ChatGPT has been muddy, at best. That doesn’t seem to be the case for custom GPTs, for a few reasons.
- Custom GPTs can be shared either privately, or publicly.
- The usual authentication mechanisms like OAuth are still in place to ensure the GPT can only be used by authenticated and authorized users.
- OpenAI enhanced their privacy controls, granting businesses the discretion to manage data-sharing preferences for individual GPTs or entire accounts.
These are very welcome advancements; now our clients can rest assured that they are in control of their data privacy, and can selectively share or not share their input data with OpenAI.
Early Wins Show Great Potential for GPTs
The potential applications for these custom GPTs are as varied as the enterprises employing them. For instance, this blog post was partially written, proof-read, and adjusted to our internal style guide by a custom-made GPT. Even at this early stage, it’s already helped us improve and streamline our internal content creation process. Looking ahead, this will boost our team’s efficiency and productivity by reducing the time contributors need to invest in drafting the post and making revisions, and freeing up valuable time for our human editors to focus on fact-checking and high-value content creation. And the best part? The custom GPT was created in a matter of minutes.

Our Verdict?
The recent advancements announced by OpenAI, including GPT-4 Turbo and the customizable GPT models, represent a significant leap forward in cementing OpenAI in the generative AI landscape.
GPT-4 Turbo, with its expanded token window, offers enhanced performance and efficiency. In combination with lower technological barriers, customizable GPT models will open the floodgates to an avalanche of new GPT use cases. Meanwhile, the shareability of GPTs could be a total game-changer. Cross-business GPT sharing has already begun (we are already sharing our helper GPTs internally), and we anticipate that the upcoming GPT Store will catapult AI into the mainstream, much like the Android and Apple App Stores have done with “dumb” applications. It is my firm belief that any organization that implements these new capabilities will not only reap lower costs, but also significant productivity gains.