


Linda Navarette April 13, 2020
A critical component in the design of any software platform is ensuring you have a pattern in place for tracing requests and troubleshooting when something goes wrong. Imagine you’re building a record processing system that has a variety of stages, and some points require human intervention.
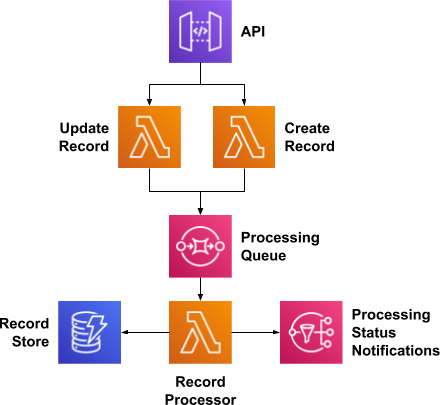
Record Processing Architecture
There are a few interaction scenarios I want to highlight:
-
User A creates Record 1 with Request 1 – it is then processed asynchronously and completes successfully
User A creates Record 2 with Request 2 – it requires intervention, either:
-
User A updates Record 2 with Request 3 – it finishes processing, OR
-
User B updates Record 2 with Request 3 – it finishes processing
-
In all of these scenarios, the record id is consistent for the duration of the request, but depending on whether the request required intervention, a new request id and potentially new user id become important for understanding the full picture. This simple architecture highlights four key challenges that any distributed architecture will face when implementing tracing:
-
Every request must be traceable throughout the entire system. While the Record Processor may not need to know which user initiated the request to be able to process a record, it is likely valuable in understanding why the record is being processed.
-
Some workflows are influenced by a number of requests, there needs to be a way to group multiple requests, potentially initiated by multiple users, to get a full picture view.
-
The “right” tracing metadata may change over time. The mechanism needs to be flexible to support when a need arises to trace a new attribute or new workflow.
-
When retro-fitting an existing architecture, it may not be designed to require or propagate tracing metadata. The contracts for every integration point may not require or even allow for this metadata to be passed, depending on what information is functionally required by a component.
A common solution is tracking a request identifier, sometimes called a correlation id, throughout the system so events related to that request can be easily correlated. This attribute doesn’t have much value beyond that and is therefore usually just a transient piece of data, passed alongside requests through potentially many services, but rarely persisted. Depending on the domain, it’s sometimes useful to bind meaningful attribution along with the request identifier. Together, this request identifier and attribution data define a “request context.” In order for the request context to be useful, it must be available to all parts of a system for any active request. Making sure that context flows from one part of the system to another is “context propagation.” How context propagates between systems components, particularly in a distributed cloud system, is dependent on the type of component (e.g. serverless functions, microservices, and queues would all accept and propagate context in different ways).
Defining Request Context
Let’s assume you have some RequestContext object which stores that transient metadata. For simplicity’s sake I’ve only included two attributes here: a user id and a request id.
public class RequestContext {
public static final String USER_ID_FIELD = "UserId";
public static final String REQUEST_ID_FIELD = "RequestId";
private String userId;
private String requestId;
// getters and setters...
}This should remain limited in scope but over time you may learn that what defines context needs to be improved or changed.
SQS Message Attributes
From our example above, the API publishes a request to either the Create Record function or the Update Record function, these then act as a publisher to the processing queue. The processing queue will be managed by Amazon Simple Queue Service (SQS), a fully managed queue service on AWS.
To send a message to an SQS queue via the AWS SDK, you really only need two things: the endpoint for the queue and the message body. There’s also the option to provide different configuration for that message, including a delay before it is visible to consumers and message attributes.
Your consumer can use message attributes to handle a message in a particular way without having to process the message body first.
We’ll use message attributes to propagate the request context along with our messages, as Record Processor doesn’t actually need that information beyond appending it to logs, this will provide the Record Processor a generic way of handling this context regardless of where the message came from (or what the message body contains). It provides the context even in situations where the message publisher sends a message body that is completely invalid and can’t be processed.
Building the Message Publisher
Let’s look at a simplified version of our Create Record function, call it Publishing Function, and assume that it requires requests to contain both a user and request identifier and then sends a message to the Record Processor via the queue. All of the AWS SDKs support injection of request handlers at different points within the lifecycle of a request. This provides a configurable way to append that context each time the client is invoked.
public class RequestContextEnrichedSqsClientRequestHandler extends RequestHandler2 {
private RequestContext context;
/**
* Creates an SQS client request handler to enrich all
* sent messages with the provided request context.
*
* @param context request context containing attributes to be appended
*/
public RequestContextEnrichedSqsClientRequestHandler(RequestContext context) {
this.context = context;
}
@Override
public AmazonWebServiceRequest beforeExecution(AmazonWebServiceRequest request) {
if (request instanceof SendMessageRequest) {
addAttributes(((SendMessageRequest) request)::addMessageAttributesEntry);
} else if (request instanceof SendMessageBatchRequest) {
// adds the message attributes from the context
// to every message in the batch
((SendMessageBatchRequest) request).getEntries()
.forEach(entry ->
addAttributes(entry::addMessageAttributesEntry)
);
}
return super.beforeExecution(request);
}
private void addAttributes(BiConsumer<String, MessageAttributeValue> addAttribute) {
addAttribute.accept(
RequestContext.REQUEST_ID_FIELD,
asAttribute(context.getRequestId())
);
addAttribute.accept(
RequestContext.USER_ID_FIELD,
asAttribute(context.getRequestId())
);
}
private static MessageAttributeValue asAttribute(String value) {
return new MessageAttributeValue()
.withStringValue(value)
.withDataType("String");
}
}This can be injected into the request lifecycle by any message publishers when an SQS client is created. The Publishing Function receives a request and passes that request context along completely independent of the message body:
public class PublishingFunction {
public void handleRequest(RequestContext requestContext, Context context) {
AmazonSQSClientBuilder.standard()
.withRequestHandlers(new RequestContextEnrichedSqsClientRequestHandler(requestContext))
.build()
.sendMessage(System.getenv("QUEUE_URL"), "hello!");
}
}Building the generic RequestContextEnrichedSqsClientRequestHandler makes this logic reusable by both Create Record and Update Record and ensures they’re using a standard pattern when providing the messages to the Record Processor.
Building the Message Consumer
On the consumption side, the message request context needs to be recomposed with the consideration that many messages may come as part of the same batch but are associated with different requests.
While in our example there’s only one SQS consumer and therefore not a need to create a standard consumption mechanism, there are many systems in which doing so would be valuable. One way to standardize this would be to provide a base implementation of an SQS event handler that any consumer can implement, eg:
public abstract class AbstractRequestContextEnrichedSqsEventHandler {
public final void handleRequest(SQSEvent event, Context context) {
event.getRecords().forEach(this::processMessage);
}
protected abstract void processMessage(SQSEvent.SQSMessage message,
RequestContext requestContext);
private void processMessage(SQSEvent.SQSMessage message) {
RequestContext requestContext = new RequestContext();
getOptionalStringAttribute(message, RequestContext.USER_ID_FIELD)
.ifPresent(requestContext::setUserId);
getOptionalStringAttribute(message, RequestContext.REQUEST_ID_FIELD)
.ifPresent(requestContext::setRequestId);
processMessage(message, requestContext);
}
private Optional<String> getOptionalStringAttribute(SQSEvent.SQSMessage message,
String key) {
return Optional.ofNullable(message.getMessageAttributes().get(key))
.map(SQSEvent.MessageAttribute::getStringValue);
}
}Each consumer then only needs to focus on the business logic around an individual request. Let’s now take a simplified form of our Record Processor, call it Consuming Function, which just logs the context along with the message it received.
public class ConsumingFunction extends AbstractRequestContextEnrichedSqsEventHandler {
@Override
protected void processMessage(SQSEvent.SQSMessage message,
RequestContext requestContext) {
System.out.println(requestContext + " message: " + message.getBody());
}
}Seeing It In Action
Now when I invoke the publisher with the following request:
{
"userId": "517a1cdc-1f7e-4476-9714-9a0a72df948c",
"requestId": "0cab5e59-d0d7-4041-9195-cb253ea4712e"
}In the logs of the consumer you can see the request context is successfully propagated:

CloudWatch Logs
Other Considerations
This approach makes a few key assumptions about the content being injected:
-
It is limited in terms of data size as well as number of attributes. At the time of writing this, only 10 message attributes are supported on any individual message, using many of those for passing transient metadata imposes a limitation on what your applications can do with message attributes.
-
It is not mission critical. This particular example is intended to provide existing services a low impact way of improving request tracing and general observability. Information that is critical to the functionality of a service would still need to be validated by that service.
Next Steps
In the original architecture diagram, there are two other integration points where this same concept can be applied. When the API is invoked, API Gateway will generate a request identifier and (assuming the API requires authentication) inject user information. A similar abstraction to the one shown for SQS Events can be built for Lambda Functions which receive requests from API Gateway to derive their request context from the request.
When the Record Processor publishes a status notification to the SNS topic, message attributes can also be appended to the publish request. Within SNS, those attributes provide subscribers the ability to subscribe to notifications based on those attributes. A user could subscribe to notifications only associated with transactions they originated (by user id) or to all notifications for a specific record.
What other strategies have you come up with for improving tracing of distributed systems? What types of contextual information have you found to be the most helpful to tracing and diagnosability? What problems are you still trying to solve? Leave a comment or reach out to me on LinkedIn.