

Secure Access Control Logic with Open Policy Agent
Secure Access Control Logic with Open Policy Agent

Chitranshu Srivastava
Chitranshu Srivastava October 25, 2023
Security solutions have never been one size fits all. Identity and access management (IAM) for any organization includes unique access control requirements that demand a tailored strategy and execution. For years, it’s why so many companies have built their own solutions from scratch. Today, however, the layers of user complexity, microservices, legacy systems, and multiple authorization levels have created so much cascading complexity, that building and maintaining your own bespoke solution has become exponentially more difficult. Even less desirable is having to modernize the solution every few years, when new types of threats render old systems obsolete, or migration upgrades offer new business potential.
In fact, many companies today have already built their customer systems on top of multiple IAM products, as they’ve encountered emerging needs that weren’t met by the product or products they started with. That may leave them maintaining multiple disparate IAM systems. The demand for advanced authorization security is only increasing, and in turn, increasing the levels of complexity. It’s one thing to not want to build and maintain a bespoke solution in this environment. It’s another to get from an overly complex system to a simplified future.
Companies facing this problem know that they need to standardize and streamline their system. While introducing a modern solution into the existing architecture is often a good long-term solution, it comes with a short-term cost: additional dependencies for every existing IAM product. Consider this: if users have been logging in and getting their access token from a custom-built system, that system’s likely been jamming everything it knows about the user into the token. Reading that information from the token and having it fetched at policy evaluation becomes a significant performance and resiliency concern. But here’s the good news: there are multiple ways to augment that policy with data needed to streamline the evaluation.
In this blog post, I’d like to share a proof of concept where we’ve assessed a few different paths for addressing this complex identity access management challenge, while establishing best practices and facilitating fundamentally sound security solution development. To do this, we’ve used Open Policy Agent (OPA), an open-source tool that offers a powerful, dynamic solution for establishing a solid authorization process that can stay intact and provide continuity even through migrations and future upgrades. While there are multiple solutions that can be used to achieve this, we’ve selected OPA because it has been around for several years, is both proven and widely familiar, and its ease of use enabled us to produce some rapid results.
Understanding Authorization Access Control
Authorization access control logic in a product may depend on contextual and environmental data, in addition to user roles. Let’s consider, for our proof of concept, a company with employees working different shifts and accessing various systems. To protect sensitive data, employee access needs to be restricted outside of their scheduled shifts. Role-based access control (RBAC) and attribute-based access control (ABAC) are the two most prevalent methods for implementing authorization access control. RBAC authorizes users based on their assigned roles, while ABAC considers all available characteristics of the user (not just their role), the resource, and the environment. ABAC is a superset of RBAC, as it can completely emulate it.
Our example scenario involves the use of ABAC, where a specific attribute, user shift, prevents the user from accessing the system outside their work hours. Here, OPA proves to be quite useful, as it’s a general-purpose policy engine that unifies policy implementation by decoupling policy decisions and policy enforcement.
Authentication and authorization are fundamental components of most software systems. Before digging deeper, it is essential to understand the distinction between the two. Authentication refers to activities that validate the identity of a user or service (i.e., determines if a user or service is who they claim to be), while authorization includes processes for specifying their access rights (i.e., what actions that identity can perform) and evaluating those rights for each interaction.
The rest of the blog post will focus on authorization. Even though there are multiple ways of providing authorization mechanisms to a system, we focused on options that meet the following properties:
- Programming language-agnostic, allowing generic setup of complex authorization rules that can be enforced across many services.
- Can dynamically evaluate policies over small-to-medium-sized data sets.
- Cloud-agnostic, so that it can be used irrespective of the cloud provider.
OPA meets these goals very well. Utilizing a high-level declarative language, named Rego, to enforce policies, OPA enables policies that can be written in code with a simplified syntax and a small set of functions and operators that are optimized for query evaluation. Rego’s primary objective is to provide policy decisions for other products or services. For instance, a policy decision may determine whether a user is allowed to make an API request or SSH to a machine. We’ve found the Rego Playground to be a particularly useful resource for testing the code and receiving instant feedback.
OPA’s decision-making process relies on three inputs:
- Data: a document that contains the information and context used to make policy decisions.
- Query Input: triggers computation and specifies the question being asked.
- Policy: encapsulates the logic on how decisions should be made based on the Data and Query Input.
For example, if my-service needs to determine if a user can make a GET request to a remote-service, Data would be a JSON document containing ACL (access-control list) information, while Policy would be a Rego file with rules that evaluates the data for the provided Query Input. The outcome of the policy decision is determined by this evaluation. The following sections will expand on this and explore how OPA can determine whether a user is allowed to access a system at a particular time based on that user’s shift-related information. The user should be prevented from accessing the system if it is done outside of the user shift.
Augmenting OPA with Dynamic Data
We’ve aimed to identify various methods that can be used to augment OPA with dynamic data. From the multiple ways specified in the OPA documentation, we’re particularly interested in pulling and pushing data for evaluation due to our requirement of having remote, dynamic, medium-to-large-sized data sets. This is an important element when dealing with multiple disparate systems that contain information necessary to make authorization decisions.
Pulling Data from an External API
We developed an API named user-shifts that retrieves shift-related information about a user, based on their user ID. This API was deployed in a Docker container. Additionally, we created an OPA service running in a separate Docker container that had its policies in place. During the evaluation, the policy called upon the user-shifts API to fetch the necessary data.
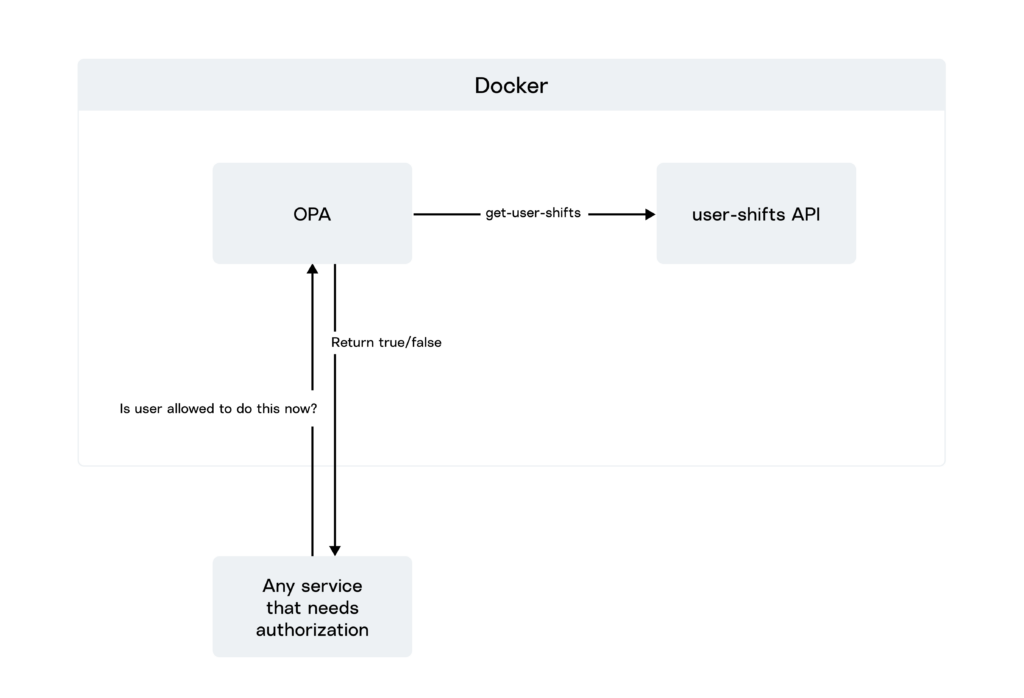
This is what the policy looks like:
policy.rego
package policy
default allow = false
user_shifts_api_endpoint = sprintf("http://user-shifts-api:8081/api/v1/userShifts/%v", [input.user.userId])
headers = {
"Content-Type": "application/json",
"Accept": "application/json"
}
available_shifts = http.send(
{
"method": "get",
"url": user_shifts_api_endpoint,
"headers": headers
}
)
response = available_shifts
allow {
some i
shiftStart = time.parse_rfc3339_ns(response[i].shiftStart)
shiftEnd = time.parse_rfc3339_ns(response[i].shiftEnd)
now = time.now_ns()
shiftStart <= now
now < shiftEnd
}One can observe that the policy evaluation involves a call to 'http.send(user_shifts_api_endpoint)', which retrieves a list of shifts assigned to the specified user. This data is then utilized for policy evaluation.
Here’s the input file:
input.json
{
"input": {
"user": {
"userId": "3"
}
}
}And the docker-compose file looks like this:
docker-compose.yml
version: '2'
services:
opa:
image: openpolicyagent/opa:0.45.0
ports:
- 8181:8181
# WARNING: OPA is NOT running with an authorization policy configured. This
# means that clients can read and write policies in OPA. If you are
# deploying OPA in an insecure environment, be sure to configure
# authentication and authorization on the daemon. See the Security page for
# details: https://www.openpolicyagent.org/docs/security.html.
command:
- "run"
- "--config-file=opa-config.yml"
- "--server"
- "--log-level=debug"
- "/policies"
volumes:
- ./opa/policies:/policies
- ./opa/opa-config.yml:/opa-config.yml
user-shifts-api:
build:
context: .
dockerfile: Dockerfile
container_name: user-shifts-api
ports:
- "8080:8080"This is what the OPA service returns when called with the input.json file:
curl localhost:8181/v1/data/policy/allow -d @opa/input.json -H 'Content-Type: application/json'
{"result":false}Pros and Advantages
- This approach is ideal when you are dealing with a massive amount of policy-related data that is necessary to make permission decisions, and you cannot load all of it into OPA.
- Permission decisions are made on totally dynamic data, which can be a huge plus for systems with frequently changing source data.
- This technique is convenient to use, as it eliminates the need to set up services explicitly designed to push data from the source into OPA.
Cons for Consideration
- If the source data doesn’t change as often as, say, multiple times a day or hour, this approach may not be the best fit, as it requires a network call for every evaluation.
Pushing Data to OPA
OPA offers a default API that allows for pushing policy data into OPA. This data is loaded into OPA’s memory, which is then used for evaluation. Let’s look at how we did this.
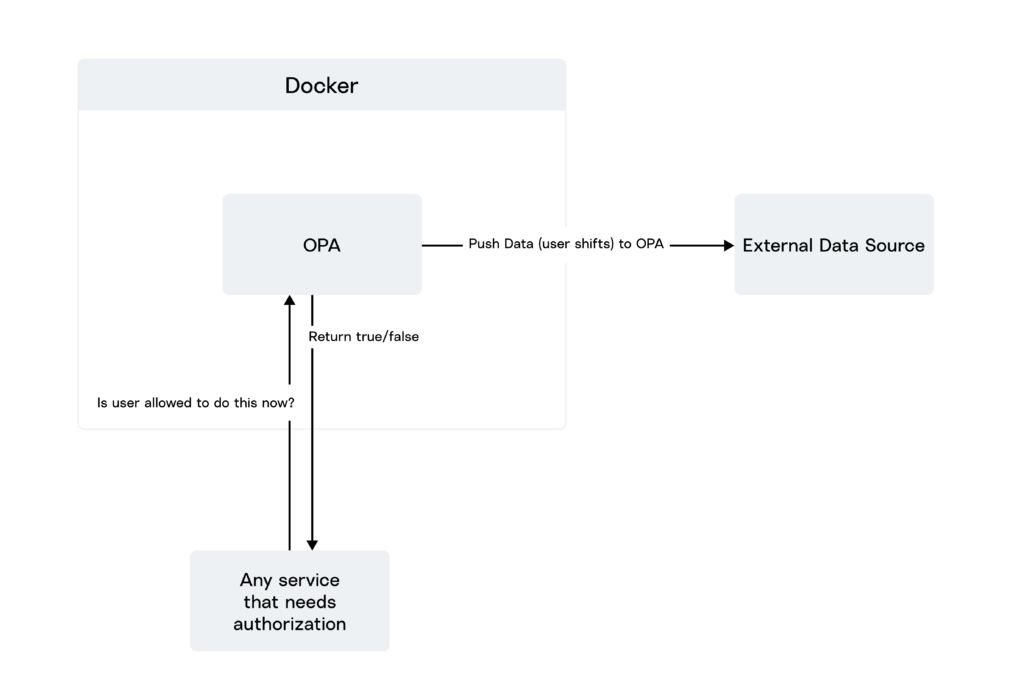
Here’s our policy for external data:
external-data-policy.rego
package external.policy
import data.external.data
default allow = false
allow {
available_shifts = data[input.user.userId]
some i
shiftStart = time.parse_rfc3339_ns(available_shifts[i].shiftStart)
shiftEnd = time.parse_rfc3339_ns(available_shifts[i].shiftEnd)
now = time.now_ns()
shiftStart < now
now < shiftEnd
}Before the data is pushed, the data field will be empty, so the response in this case will be the default value: false.
Here is a file with data that needs to be pushed:
external-data.json
{
"2": [
{
"shiftStart": "2023-06-04T19:26:15.65219Z",
"shiftEnd": "2023-06-05T01:26:15.652191Z"
},
{
"shiftStart": "2023-06-04T12:26:15.652156Z",
"shiftEnd": "2023-06-04T19:26:15.652186Z"
},
{
"shiftStart": "2023-06-04T19:26:15.65219Z",
"shiftEnd": "2023-06-05T01:26:15.652191Z"
}
],
"3": [
{
"shiftStart": "2023-06-04T19:26:29.101929Z",
"shiftEnd": "2023-06-05T01:26:29.10193Z"
},
{
"shiftStart": "2023-06-04T19:26:29.101929Z",
"shiftEnd": "2023-06-05T01:26:29.10193Z"
}
]
}This is how we can do a curl request to push the data using OPA API:
curl -X PUT localhost:8181/v1/data/external/data -d @opa/external-data.json Now, our external-data-policy.rego policy would have the data required to do the evaluation.
Pros and Advantages
- This approach eliminates the need for an extra network call during policy evaluation, resulting in superior network efficiency and faster evaluation.
- Furthermore, you can optimize it by solely pushing updates, which would enhance memory efficiency and provide better control of the distributed data into OPA.
Cons for Consideration
- Implementing this approach to import new kinds of data from various sources necessitates meticulous coordination among them, leading to increased maintenance.
- Since the data is always stored in memory, it is imperative to ensure that the latest data is re-pushed in the event of server crashes or restarts.
- If disaster recovery measures are in place, such as multiple OPA instances, it is crucial to ensure that the data is synchronized across all instances.
Although our experiment for this scenario focused on push and pull methods, there are lots of ways to augment OPA with dynamic data. Feel free to explore them to see what works for you.
Evaluating Authorization Security Outcomes
As you work with OPA, compiling significant observations will help to inform best practices for your own organization’s use case. When using OPA version 0.45.0 for our proof of concept, we discovered that the ‘http.send’ method in Rego does not handle errors very effectively. For instance, the ‘available_shifts’ variable in ‘policy.rego’ may contain error messages returned by the API (such as 404, 400, etc.). However, if the URL is unreachable, or if the connection is refused, the variable would simply contain a blank value, causing the policy to just halt.
If you have dynamic data that undergoes frequent changes, the pulling method might seem appropriate. However, in the case of authorization-related data, it is uncommon for it to change more often than it is utilized. On the other hand, if pushing the data seems more appropriate, it is essential to consider that the data will always be stored in memory. Therefore, memory optimization is a crucial ingredient to a successful push implementation.
The OPA documentation provides a summary evaluation of ideal solutions to use in various scenarios. For an ABAC solution that can be used with any type of cloud or on-prem, OPA offers an expressive policy language. Paired with that flexibility, it’s a great tool for solving fine-grained access control logic problems. OPA is not the only solution available for this – offerings from AWS, Google, Microsoft, as well as emerging tools like Oso Cloud, provide a variety of options to establish sound authorization processes. As you familiarize yourself with all of them, the most important thing is that you make sure the tools you select suit the requirements of your own architecture.